Dominic Cronin's weblog
Spoofing a MAC address in gentoo linux
I spent a few hours this weekend fiddling with networking things at home. One of the things I ran into was that the DHCP server provided by my ISP was behaving erratically. Specifically, it was being very fussy about giving out a new lease. It would give out a lease to a Windows 7 system I was using for testing, but not to my Gentoo server. At some point, having spent the day with this kind of frustration, I was ready to put up with almost any hack to get things running. Someone on the #gentoo IRC channel suggested that spoofing the MAC address that already had a lease might be a solution. Their solution was to do this:
ifconfig eth0 down ifconfig eth0 hw ether 08:07:99:66:12:01 ifconfig eth0 up
Here, you have to imagine that eth0 is the name of the interface, although on my system it isn't any more. (Another thing I learned this weekend was about predictable interface names.) You should also imagine that 08:07:99:66:12:01 is the mac address of the network interface on my Win7 system.
The trouble with this is that it doesn't integrate very well in the standard init scripts that get things going on a Gentoo system. Network interfaces are started by running /etc/init.d/net.eth0 (although that's just a link to another script). The configuration is to be found in /etc/init.d/net where you can add directives that control the way your network interfaces are configured. The most important of these are the ones that begin with "config_". For example, to set up a static IP for eth0, you might say something like:
config_eth0="192.168.0.99 netmask 255.255.255.0 brd 192.168.0.255"
or for DHCP it's much simpler:
config_eth0="dhcp"
So my obvious first try for setting up a spoofed MAC address was something like this:
config_eth0="dhcp hw ether 08:07:99:66:12:01"
but this didn't work at all. Anyway - after a bit of fiddling and more Googling (sorry - I can't remember where I found this) it turned out that there's a specific directive just for this purpose. I tried this
mac_eth0="08:07:99:66:12:01" config_eth0="dhcp"
It works a treat. Note that the order is important, which is obvious once you know it I suppose, but wasn't obvious to me until I'd got it wrong once.
The good news after that was that for an established lease, everything worked rather better.
Moving your Tridion databases
As part of setting up my new laptop, I installed MSSQL and obviously I wanted to have my existing Tridion databases available. My Tridion image had previously not had a database - I had that running natively on the old laptop, but I'd decided to go with a more conventional approach and run it in the image with Tridion. This transition had a couple of interesting moments, and hence this post.
Moving the databases and getting MSSQL security working again.
The moving part was fairly simple. I just detached all the databases, and copied the pairs of .MDF and .LDF files over to the new location and attached them.
Once you've done this, you'll find that in each database, if you look under Security/Users, you'll find a User with a name that matches the login that you use in your Tridion configuration... for example: TcmDbUser. Unfortunately, this isn't enough. There are (at least) two kinds of User. The one you can see in your database (this is strictly a "database principal") can't be used for logging in. For that you need a "server principal", and these are to be found in your MSSQL instance under Security/Logins. For everything to work correctly, there needs to be a mapping between the database principal and the server principal. You can see this if you look in a correctly configured system. Right click on the login and open the properties, and open up the user mapping page. It should look something like this:
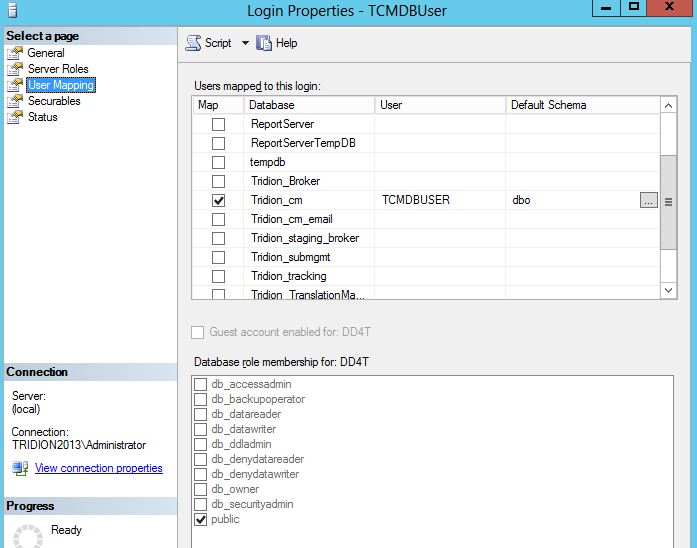
So what we're aiming for is to have a matching Login and database User, with the same name. Creating a Login is easy enough, but if you try to add the mapping by hand in the User Mapping page, it will fail, because it wants to create a database user, and a database user with the same name already exists. (You could delete it, but then you'd have a world of pain trying to figure out all the properties and settings that the Tridion database scripts take care of automatically. I'm not even sure if support would ever talk to you again if you did this.)
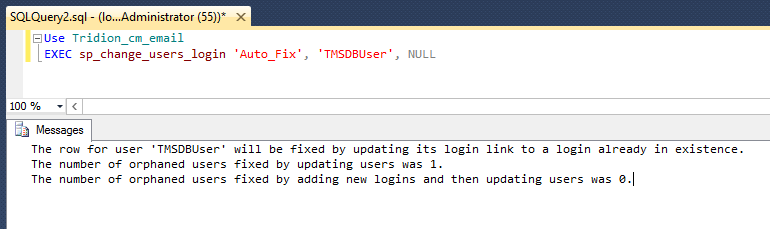
Fortunately, there's a better way. You can do it via SQL with various ALTER USER commands, but then you are going to be deeper into the security features of MSSQL than any normal person ought to wish for. (In this context, DBA's aren't normal, but then they won't be needing to read this blog post, will they?) However, you don't need to figure out all that SQL, because there's a system procedure (sp_change_users_login) that does exactly what you want. As long as your Login and User have the same name, you can just use the Auto_fix method, like this:
Remembering the database settings you'd forgotten about.
So I had all the MSSQL stuff correctly set up, or so I thought, but when I started to try to use the Tridion GUI, I kept getting error notifications in the Message centre.
A network-related or instance-specific error occurred while establishing a connection to SQL Server. The server was not found or was not accessible.
Verify that the instance name is correct and that SQL Server is configured to allow remote connections. (provider SQL: Network interfaces error, 26 - Error locating Server/Instance Specified)
This was pretty odd. I could see most of the GUI working fine, and publications were listed OK, but other lists weren't populated. I speculated that it might only be lists served via service calls that had problems, but when I checked the core service, it was able to list out my entire system. I spent quite some time fiddling with various settings and checking that named pipes etc., were configured correctly, before I eventually got smart enough to check T-REX again.In an old post from 2011, Rick Pannekoek suggested that a similar problem might be caused by the outbound email configuration.
Sure enough - I'd forgotten that outbound email has it's own database configuration (if I'd ever known it - the installer sets it all up and mostly you never need to look there, unless you're actually doing outbound email). Anyway - I certainly hadn't realised that this would break the Content Manager's GUI.
A quick visit to:
C:\Program Files (x86)\Tridion\config\OutboundEmail.xml
and then a bit of fiddling with decrypting and re-encrypting (there are scripts for this that come with the installer), and I had my system in fully working order.
Parameter type quirks of the XSLT mediator
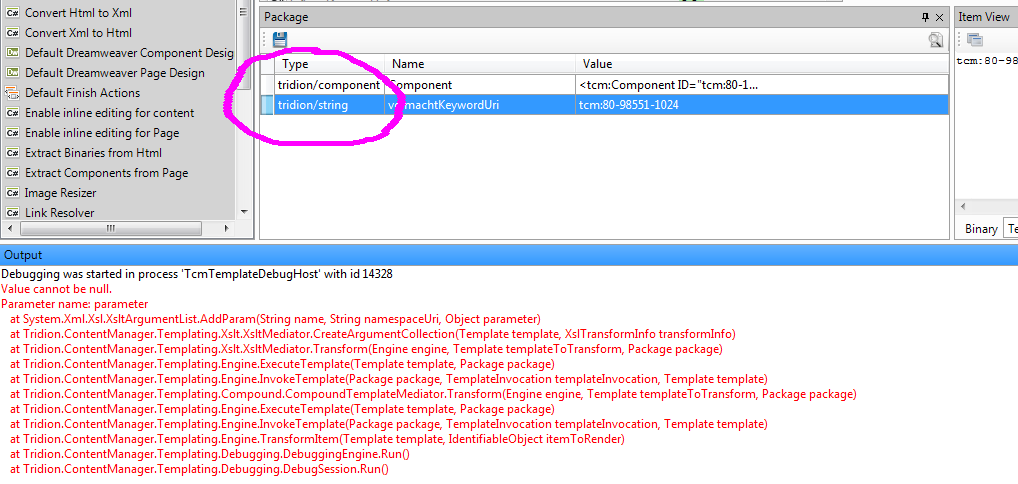
Today I was working on a template with an XSLT building block. I'd added a parameter to the package further up, and expected to use it simply by having an <xsl:param/> element with a matching name. Instead I got the error message you can see in the screencap below... Value cannot be null, Parameter name: parameter.
So what's going on here? Well I had a bit of a dig... (obviously by using my secret powers, and nothing as humdrum as technology) and came up with a couple of interesting things. Firstly, the way I'd imagined things was all wrong. I had assumed that the mediator would loop through the package variables, and add them as parameters to the XSLT. In fact, it's the other way round. The mediator parses the XSLT to get the param elements that are declared, and loops through these to see if it can find a satisfactory parameter to add.
If you look in the documentation, you will find that there are some "magic" parameter names that will cause the mediator to pass various relevant data items as parameters. These are tcm:Publication, tcm:ResolvedItem, tcm:ResolvedTemplate and tcm:XsltTemplate. In addition to these documented parameters, tcm:Page and tcm:ComponentTemplate would also appear to work under the correct circumstances, but of course, if you want your templates to be future-proof, it's better not to use such undocumented features, especially seeing as you could just add the relevant items as XML to your package, and have the same result. It all reminds me of the old XSLT component templates, that also had magic parameters that very few people knew about.
Anyway, back to my bug - for it is indeed a bug. In addition to providing magic parameters, of course the mediator also wires up parameters that are in the package. So - having found a parameter name in the XSLT, it looks for a package item with the matching name. If the item is of type "text" or "html", then it gets added as a string. For any other item type, it tries to get an appropriate XmlDocument and add that. If this process fails, any exceptions get swallowed, and instead of an XmlDocument the "parameter" parameter of AddParam becomes null. And then we see the aforementioned "Value cannot be null. Parameter name: parameter" message, which is the .NET framework quite correctly checking its input values and refusing to play.
The solution is easy - instead of using ContentType.String when I added my parameter to the package, I used ContentType.Text, and everything worked like a charm. But not obvious, and hence the blog post. I'm sure to forget this, and having it in my "external memory" might help.
It's easy to see how this could happen. In fact, it's our old friend LOLA. The GetAsXmlDocument() method of a Templating Item returns a null if it can't manage to return the relevant XmlDocument - for all I know, this is the correct semantics for such a method. Maybe there are very good reasons for it. Still - if you're writing client code, and you don't know this, you'll fail to do the null check, and things will break. FWIW the null check is also missing in older versions of the mediator.
So - there - I've got that off my chest. I should probably report this to customer support. But it's the weekend, and seeing as my stuff works, and the answer is now google-able, I might possibly not have that much energy :-)
Managing the Tridion Core service powershell module as a git submodule
N.B. Peter has changed the structure of the module (as he has every right to do, and I'm not complaining) - what this means is that this blog post is pretty useless other than as an exercise in poking at things. Maybe I'll figure it out, but in the meantime, assume that this technique won't work.
I spend quite some time fiddling with various powershell implementations on my Tridion image. Whenever there's a place where I do experimental things like this, I run the risk that I'm going to break something so, at the very least, I usually do a quick "git init" in the directory, add the files and commit them. Then I have the benefit of version diffs and rollbacks if I need them. The next step comes when I realise that it's something I'm going to work on over a longer time, and that I really would prefer not to lose. At this point, I usually go on to my linux server and init a bare git, and then push from whereever I'm working.
Today I reached this second phase with the WindowsPowerShell directory of the Administrator account on my Tridion image. (It's about time, because I'm busy preparing a talk for the Tridion Developer summit in a couple of weeks, and well, losing my scripts would put a kink in my plans, to say the least.
In any case, I'd realised that I was running quite an old version of Peter Kjaer's Tridion-CoreService module. This module is the basis of pretty much any effort to use the Tridion core service from the powershell, and as this is the subject of my upcoming talk, I figured I should at least be doing my demos on the current version.
If you go to the github page for the module, you'll see that Peter's provided installation scripts which will help you to get up and running, but of course, if you have git installed, it makes just as much sense to clone the module directly. The only problem I had was that Modules are normally located in the Modules directory under the WindowsPowerShell directory. (You can add other locations to env:PSModulePath, but for what I wanted, that wasn't ideal.)
Fortunately, GIT is widely used for projects that make use of other projects, and there is very good support built in, by way of git-submodule. As my main git repository for the powershell stuff is directly in the WindowsPowerShell directory, all I needed to do was add Peter's module as a submodule with the right path.
In fact I just clicked on the menu option in Tortoise Git, but the basic command looks something like this:
git submodule add --name Modules/Tridion-CoreService git@github.com:pkjaer/tridion-powershell-modules.git Modules\Tridion-CoreService
With this in place, git understands that the Tridion-CoreService code belongs to Peter's module, and if he releases a new version, I can just pull. And of course, my own changes go in my own repository. Adding a submodule adds a .gitmodules file in your repository, so if I ever clone my WindowsPowerShell repository into another server, the location of Peter's repository can be retrieved, and the files pulled from there.
One word of warning. This is not the official release process for the Tridion-CoreService module. That is described here. As the module is pretty much a one-man affair, it's not unreasonable that there's only the master branch, so pulling from it is at your own risk. Personally I'm happy with the small risk, as it helps me to keep my development system a bit tidier - and heck - if it breaks, we'll fix it!
.
The complete list of webdav extensions
Don't you just hate it when someone asks a question that you don't really know the answer to? Something that you probably have a fair idea about, but a definitive, authoritative answer... well you're not quite there. So there I was hanging out with the other SDL Web MVPs, and one of them throws out the question: "Anyone have a list of WebDAV file extensions for all Tridion items?"
I knew most of them, but for some reason I couldn't let it lie, and I dug around for a bit until I thought I had the complete list. I even bet the guys a beer that they couldn't find one I'd missed, and so far I haven't been successfully called on it.
For what it's worth, here's what I came up with:
Firstly - there is no complete list, because Tridion is extensible. There are two places where "wild" WebDAV file extensions can occur. Firstly, anything that gets processed by a mediator is wired up in the Tridion.ContentManager.config file. There's a section called templateTypeRegistry where you'll find (on a standard system) tctcmp, tptcmp, tbbcmp, tbbasm, tbbcs, dwt and xslt. On my system I also found cshtml, because I have the razor mediator installed.
The other place where you can't really make a definitive list is multimedia components. A multimedia component's webdav url has a file extension of jpg, png, doc, pdf or whatever. I suspect this is simply the extension of the file you uploaded to make the multimedia component, although I didn't dig in far enough to know this for certain. Maybe there's a relationship with the multimedia type.
Then you have some standard built-in extensions:xml, xsd, tpg, tkw and ttg, for Component, Schema, Page, Keyword, and Target Group respectively.
If you look at the compound template types, tctcmp, tptcmp and tbbcmp, you can see that they are different from legacy page and component templates. The legacy ones, if I remember correctly, were tpt and tct.
That pretty much completes the list. Organisational items like folders and structure groups don't have file extensions on their WebDAV Urls. This makes sense, because they are containers, and in most webdav clients they'll end up looking like folders. And then there are various types that just don't have WebDAV urls at all. These are typically system items such as publication targets and the like.
So there you have it. It probably counts as utterly useless trivia, but it kept me occupied for a short while.
The Tridion XSLT mediator, and page templates that don't template pages
My current customer is in the process of upgrading to Tridion 2013, and as part of that, switching over from the old XSLT mediator to the new. By the new one, I mean the one that was released by SDL as part of the 2013 product. The new one is very similar to the old one, and changing over hasn't created any significant problems, but I came across a quirk this week that I thought worth sharing.
The symptoms were pretty odd, and it took me a while to figure out what was happening. One of the page templates was emitting entirely the wrong content. In fact, instead of templating out a page, what I could see was more or less a copy of the XML of a component that was on the page. If you have the same problem, your symptoms may be different, depending on how you've written your XSLT template. It's also possible that you don't get any output at all, or something different.
Obviously, what the XSTL mediator does, is use your XSLT to transform an XML document. The question is - where does the XML document come from? The documentation states "By default, the XSLT template transforms the item called Component (if the Template Building Block is part of a Component Template) or Page (if part of a Page Template)."
This is not really as true as you might hope. It would actually be possible for the mediator to determine the type of item being rendered, but it doesn't do that. What it does by default is look in the package for an item called "Component", and if it finds one, that's what it transforms. Only then does it look to see if there's an item called "Page". If you ask me, that logic is backwards, as it's far more unlikely that a Component package has a Page item than the other way round. (There's even a standard Tridion TBB whose purpose is to add a Component item to a Page package.)
Anyway - all is not lost - the fix is quite simple. It's possible to override the default behaviour by specifying an input item. The old mediator used template building block parameters to control this behaviour, and IMNSHO that was a good choice in the context. With the new mediator, you do the same thing by using a processing instruction in the XSLT itself, or specifically by setting an attribute on the PI. In fact, if you look at the documentation, you can combine the two techniques, but that would surely be overkill for this.
So the bottom line is that in a page template, you should have something like this:
<?XsltMediator inputItemName="Page"?>You may have noticed that I said "should". Yes - really... "should". Then you're clear that you want your page to render the Page item, even if at some point in the future, one of your colleagues decides to add an item called Component to the package. When the default behaviour is as non-obvious as this, it's wise not to rely on the defaults.
This was a public service announcement - or perhaps it was my penance for not spotting sooner what was going on.
Getting the complete component XML
One of the basic operations that a Tridion developer needs to be able to do is getting the full XML of a Component. Sometimes you only need the content, but say, for example that you're writing an XSLT that transforms the full Component document - you need to be able to get an accurate representation of the underlying storage format (OK - for now let's just skate over the fact that different versions have different XML formats under the water)
In the balmy days of early R5 versions, this was pretty easy to do. The Tridion installation included a "protocol handler", which meant that if you just pasted a TCM URI into the address bar of your browser, you'd get the XML of that item displayed in the browser. This functionality was actually present so that you could reference Tridion items via the document() function in an XSLT, but this was a pretty useful side effect. OK... you had to be on the server itself, but hey - that's not usually so hard for a developer. If you couldn't get on the server, or you found it less convenient, another option was to configure the GUI to be in debug mode, and you'd get an extra button that opened up some "secret" dialogs that gave you access to, among other things, the XML of the item you had open in the GUI.
Moving on a little to the present day, things are a bit different. Tridion versions since 2011 have a completely different GUI, and XSTL transforms are usually done via the .NET framework, which has other ways of supporting access to "arbitrary" URIs in your XSLT. The GUI itself is built on a framework of supported APIs, but doesn't have a secret "debug" setting. However, this isn't a problem, because all modern browsers come fully loaded with pretty powerful debugging tools.
So how do we go about getting the XML if we're running an up-to-date version of Tridion? This question cropped up just a couple of days ago on my current project, where there's an upgrade from Tridion 2009 to 2013 going on. I didn't really have a simple answer - so here's how the complicated answer goes:
My first option when "talking to Tridion" is usually the core service. The TOM.NET API will give you the XML of an item directly via the .ToXml() methods. Unfortunately, someone chose not to surface this in the core service API. Don't ask me why? Anyway - for this kind of development work, you could use the TOM.NET. You're not really supposed to use the TOM.NET for code that isn't hosted by Tridion (such as templates) but on your development server, what the eye doesn't see the heart won't grieve over. Of course, in production code, you should take SDL's advice on such things rather more seriously. But we're not reduced to that just yet.
Firstly, a brief stop along the way to explain how we solved the problem in the short term. Simply enough - we just fired up a powershell and used it to access the good-old-fashioned TOM.COM. Like this:
PS C:\> $tdse = new-object -com TDS.TDSE
PS C:\> $tdse.GetObject("tcm:2115-5977",1).GetXml(1919)
Simple enough, and it gets the job done... but did I mention? We have the legacy pack installed, and I don't suppose this would work unless you have.
So can it be done at all with the core service? Actually, it can, but you have to piece the various parts together yourself. I did this once, a long time ago, and if you're interested, you can check out my ComponentFactory class over on a long lost branch of the Tridion power tools project. But that's probably too much fuss for day to day work. Maybe there are interesting possibilities for a powershell module to make it easier, but again.... not today.
But thinking about these things triggered me to remember the Power tools project. One of the power tools integrates an extra tab into your item popup, giving you the raw XML view. I'd been thinking to myself that the GUI API (Anguilla) probably had reasonably easy support for what we're trying to do, but I didn't want to go to the effort of figuring it all out. Never fear: after a quick poke around in the sources I found a file called ItemXmlTab.ascx.js, and there I found the following gem:
var xmlSource = $display.getItem().getXml();
That's all you need. The thing is... the power tool is great. It does what it says on the box, and as far as I'm concerned, it's an exceedingly good idea to install it on your development server. But still, there are reasons why you might not. Your server might be managed by someone else, and they might not be so keen, or you might be doing some GUI extension development yourself and want to keep a clear field of view without other people's extensions cluttering up the system. Whatever - sometimes it won't be there, and you'd still like to be able to just suck that goodness out of Tridion.
Fortunately - it's not a problem. Remember when I said most modern browsers have good development tools? We use them all the time, right? F12 in pretty much any browser will get you there - then you need to be able to find the console. Some browsers will take you straight there with Ctrl+Shift+J. So you just open the relevant Tridion item, go to the console and grab the XML. Here's a screenshot from my dev image.

So now you can get the XML of an item on pretty much any modern Tridion system without installing a thing. Cool, eh? Now some of you at the back are throwing things and muttering something about shouldn't it be a bookmarklet? Yes it should. That's somewhere on my list, unless you beat me to it.
Hotfix rollups are the new Service Pack
I was recently surprised to learn that a Hotfix Rollup shipped from SDL Tridion is something quite different to what you'd expect from the title. For at least the last 10 years, and probably longer, the distinction between a hotfix and a service pack was very simple:
Service Pack
A collection of product improvements shipped between full version releases. The improvements would include bug fixes, and possibly new features, but never "breaking" changes. The intention was that customers should install the latest service pack for their current version. The service pack would have been thoroughly tested by R&D and would be the basis for on-going support until the next release.
Hotfix
If an issue was found in software in the field, a hotfix could be created to address this issue. There wouldn't be an installer - just some files and some instructions. Often a hotfix would be seen as suitable for any customer to install, but other hotfixes were riskier, and if you didn't have the problem, installing the hotfix would be a bad idea. Hotfixes were tested by customer support. The next service pack or full release would supersede any hotfix. In a reasonably thorough risk-management strategy, the standard play was to avoid taking hotfixes until you needed them. The official advice from Tridion as of 2011 was this:
IMPORTANT NOTE: Hotfixes are released at the discretion of SDL Tridion based on technical complexity, customer business requirements and schedules. Hotfixes are made and tested only for the described problem on a particular environment/configuration and therefore should only be installed if approved by SDL Tridion Customer Support. Hotfixes should be replaced as soon as possible by the subsequent service pack where the problem is fixed.
And then along came Hotfix Rollups...
Hotfix rollups
You might be forgiven for thinking that a hotfix rollup was, well a sort of erm... roll-up of hotfixes. A collection of hotfixes. A gathering together of a handy bunch of hotfixes to make life easier for the less risk-averse who like to install everything. (Like me, when I'm installing my own dev image. Love the handiness of it.) That's what the name means in any normal interpretation of the English language. The point here is that this is not what SDL Tridion mean when they say Hotfix Rollup. From discussions with various SDL people, it seems that they see a hotfix rollup as having the following characteristics:
- It is not expected to cause any problems on your system and can safely be installed.
- To this end, it has been tested by the relevant specialists in R&D
- In the same way that you are expected to install a service pack, you are expected to install a hotfix rollup. Should further hotfixes become necessary, they will have the hotfix rollup as a dependency, not specific hotfixes. (This means that if you need that hotfix, you'll end up installing the hotfix rollup too, probably at a moment that you'd prefer to have chosen yourself.)
This is my best understanding at the current moment, but I am not aware of any formal communication from SDL that makes this clear, or otherwise updates the advice from 2011. Obviously, feel free to get formal confirmation via the usual channels
And as for you, SDL: your customers' risks are not your risks. You owe it to your customers to communicate correctly and in a timely way about this kind of thing. If anyone thought this would engender trust and confidence, that person was not thinking clearly. I wouldn't be saying this, but people out in the field often spend significant effort trying to balance risks like this, and it's in all our interests to make sure it goes well.
The Tridion Bookmarklet Challenge: We have a winner!
Those of you who have been following the Tridion bookmarklet challenge from the beginning will already know this, of course, but we have a winner. As I noted in my round up of the entries, Alexander Orlov (UI Beardcore) had, in addition to his own entry, the highest number of credits from other entrants for his assistance. It's fitting, therefore, that his entry found itself voted to the top of the heap, and came in as the clear winner with 15 votes at the close of play. Congratulations therefore to Alexander, not only for technical excellence, but also for his contribution to the true spirit of the competition.
The GIT command line is actually useful
I tend to use a mix of GIT clients. Tortoise GIT is probably my main workhorse, as most of the time, managing my work via Windows Explorer is a pretty good model. Some people at the office are keen on Atlassian SourceTree, so I'll probably end up using that on projects where that's the standard tooling. Microsoft Visual Studio 2013 works pretty well with GIT, and there are plug-ins for earlier versions.
So why would I ever need a command line client, you might ask? And yet, I habitually also install GIT for Windows, (and trust me, it's not because I need another graphical client). I actually like having a command line client around, as I sometimes have the idea that some things might be simpler that way. I'm also scratching an itch to always learn a couple of ways of doing something, but realistically, I don't invest much effort in learning the command line, but I like to have it around, just in case... even at the cost of occasionally having to fend off accusations that I'm just trying to be some kind of geek..... <sigh>
And then, one day at work this week, it actually turned out that the command line was the only way to get the job done. I needed to clone a repository that was on a remote machine on a file share. Should be easy you'd think, but the remote location needed to be specified as a UNC address, and Tortoise GIT just wouldn't cope with the syntax.
So I reached for the command line, and after some cursory research it turned out what I needed to do was:
git remote add blah //SERVERNAME/c$/code/Blah
Once I'd done that, I could continue to use Tortoise, as the "blah" repository just showed up in the list...
So there you have it. I am completely justified and vindicated in keeping this software on my computers. :-) Maybe I'll practice a bit more and find some other good reasons to keep it around.