Dominic Cronin's weblog
Upgrading SDL Web Microservices - don't copy new over old
I've just broken my Tridion system. I had a perfectly good SDL Web 8.1.1 installation, and I've broken it upgrading to 8.5. This is really annoying. I'm gritting my teeth as I type this, and trying not to actively froth at the mouth. It's annoying for two reasons:
- The documentation told me to
- I got burned exactly the same way going form 8.1 to 8.1.1 and I don't seem to have learned my lesson.
So what exactly am I ranting about? Let me explain.
Take the discovery service as an example, but the same thing applies to the other services. Look at the documentation for Upgrading the Discovery Service. Check out the highlighted line below:

Doing this goes against the grain for anyone with experience of setting up servers. Copying a clean "known good" situation over a possibly dirty implementation and expecting it to work is asking for trouble. I'd never have written these instructions myself. What on earth was I thinking when I blindly followed them?
The service directory that you're attempting to overwrite contains a lib directory full of jars, and a services directory containing yet two more directories of jars. What you want to do is replace the jars with their new versions. This would be fine if all the jars had the same name as before, and there weren't any that shouldn't be there any more. As it is, the file names include their version numbers, so you end up with both versions of everything, like this:
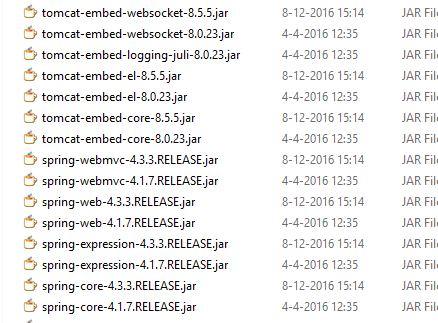
This results in messages like "Class path contains multiple SLF4J bindings" and ensures that your services don't start. The solution is simple enough. Go to the various directories, and make sure that they contain only the jars from the 8.5 release.
Fortunately, I'm still feeling very positive about the folks at SDL in the wake of having received the MVP award again. I suppose I'll forgive them.... once I finish cleaning up the rest of my services.
Update: After posting this fairly late last night, it's now not even lunch time the following day, and I've already been informed that SDL have seen this, and are already taking action to update the documentation. That's pretty good going. Thanks
System refresh: new architecture for www.dominic.cronin.nl
It's taken a while, and the odd skinned knuckle and a bit of cursing, but I can finally announce that this site is running on...erm.. the other server. Tada! Ta-ta-ta-diddly.... daaahhhh!!!!
Um yeah - I get it. it's not so exciting is it really? The blog's still here, and it's got more or less the same content. It doesn't look any different. Maybe it's a tiny smidgin faster, but even that's more likely to do with the fact that we switched over to an ISP that actually makes use of the glass that runs in to our meter cupboard.
But I'm excited. Just a bit, anyway. Partly because it's taken me months. It needn't have, but it's the usual question of squeezing it into the cracks between all the other things that need to get done in life. That and the fact that I'm an utter cheapskate and I don't want to pay for anything. There's also plenty not to be excited about. As I said, the functionality is exactly as it was. The benefits I get from it are mostly about the ability to do things better going forward.
So what have I done? Well it all started an incredibly long time ago when I started tinkering with docker. I figured that the whole containerisation technology thing had such a lot of potential that I ought at least to run docker on my own server. After all, over the years, I'd always struggled with Plone needing to have a different version of Python than the one available in the current Gentoo ebuilds. I'd attempted a couple of things, including I think an early version of what became LXC, but then along came virtualenv, which made the whole thing moot.
Yeah, well - until I wanted to play with docker for itself. At this point, I just thought I'd install it on my server, and get going, but I immediately discovered, that the old box I was running was 32-bit, and docker is just far too hip to run on anything so old-fashioned. So I needed a new server, and once I'd realised that, that's when the whole thing started. If I was going to have a new server, why didn't I just containerise everything? It's at this point that someone inevitably chips in with a suggestion that if I weren't such a dinosaur, I'd run it on the cloud, wouldn't I? Well yes - sure! But I told you - I'm a cheapskate, and apart from that, I don't want anyone's soul-less reliability messing with my carefully constructed one-nine availability commitment.
Actually I like cloud tech, but frankly, when you look at the micro-budget that supports this site, I'd have spent all my time searching out a super-cheap host, and even then I'd have begrudged it. So my compromise with myself was that I'd build it all very cloudy, and then the world's various public clouds would be my disaster recovery plan. And so it is. If this server dies, I can get it all up in the cloud with a fairly meagre effort. Still not going to two-nines though.
So I went down to my local high street where there's a shop run by these Indian guys. They always have a good choice of "hardly used" ex-business computers. I think I shelled out a couple of hundred Euros, and then I had something with an i5 and enough memory, and a couple of stupidly big disks to make a raid. Anyway - more than enough for a web server - which is just as well, because pretty soon it ends up just being "the server", and it'll get used for all sorts of other things. All the more reason to containerise everything.
I got the thing home, and instead of doing what I've done many times before, and installing Gentoo linux, I poked around a bit on the Internet and found CoreOS. Gentoo is a masochist's delight. I mean - it runs like a sports car, but you have to own a set of spanners. CoreOS, on the other hand, is more or less maintenance free. It's built on Gentoo's build system, so it inherits the sports car mentality of only installing things you are going to use, but then the guys at CoreOS do that, and their idea of "things you are going to use" is basically everything that it takes to get containers up and keep them running, plus exactly nothing else. For the rest, it's designed for cloud use, so you can install it from bare metal to fully working just by writing a configuration file, and it knows how to update itself while running. (It has a separate partition for the new version, and it just switches over.)
So with CoreOS up and running, the next thing was to convert all the moving parts over to Docker containers. As it stands now, I didn't want to change too much of the basics, so I'm running Plone on a Gentoo container. That's way too much masochism though. I'd already been thinking I'd do a fresh one with a more generic out-of-the-box OS, and I've just realised I can pull a pre-built Plone image based on Debian (or Alpine). This gets better and better. And I can run it all up side-by-side in separate containers until I'm ready to flip the switch. Just great! Hmm... maybe my grand master plan was just to get to Plone 5!
The Gentoo container I'm using is based on one created by the Gentoo community, which you can pull from the Docker hub. Once I found this, I thought I was home and dry, but it's not really well-suited to just pulling automatically from a docker file. What they've done is to separate out the portage tree into a separate container. This is smart, because you are unlikely to want the whole of portage in your container for any given purpose that makes you want to run Gentoo. What you do instead is mount the portage data using docker's --volumes-from argument. With it mounted, you can run emerge and install whatever packages you need, and then at runtime you get to run a much slimmer system. Which is great, but it means you have to create and store your own image manually rather than using a dockerfile. (At least, that's how it ended up for a noob like me, once I realised that dockerfile doesn't have an equivalent of --volumes-from.)
My goal was to set up CoreOs to automatically pull the docker images it needed, and run some setup commands. This meant that I'd need to have my personalised Gentoo image available somewhere. Some of the data in there was sensitive, so I went looking for a private Docker registry that I could upload it to. There are plenty of private registries, but most of them aren't free. (If you don't mind the whole world pulling your containers, then free registries abound.) I eventually found https://canister.io/, which suited my needs. That said, my needs aren't much. If I ever need an alternative to canister, I'll probably look at Google Cloud Platform, which isn't free but has a private container registry where you only pay for storage and data egress, at pretty reasonable rates. Or I could just host it myself, but that's maybe too many eggs in the same basket.
Meanwhile, my very next step ought most probably be to get backups sorted out. The "Dockerish" way to do this is to run up yet another dedicated container to deal with just this concern. Then if I want to host it separately, and my backup approach changes, nothing else needs to. Once I have the backups sorted out, it will definitely be worth the while to tidy things up so that I really can just push to the cloud if needs be. The way it's set up now, I could be up and running again very quickly but we're probably talking hours rather than seconds.
I'm really enjoying the flexibility that containerisation gives me, although it's definitely important to get into the right mindset. Being able to build containers that will run on a really generic platform is quite liberating.
Using the Powershell to parse columns out of strings
I've been kicking the tyres on Docker, and after a fairly short while I noticed that my list of containers was getting a little full. I decided to clean up, and after a quick look at the documentation, realised that I'd first have to run "docker ps -a" to get a list of all my containers, and then filter the list to get the ones I wanted to delete. (The alternative, was to read through the list, and manually execute "docker rm" on each one that I wanted to delete, and I'm far too lazy for that.)
Here's what the output from "docker ps -a" looks like
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f7a3b9bb073c dominiccronin/gentoo "/bin/bash" 33 minutes ago Exited (127) 33 minutes ago adoring_bell
2ec710c32df0 dominiccronin/gentoo "/bin/bash" 16 hours ago Exited (0) About an hour ago hungry_pare
7805ed925e51 gentoo/portage "sh" 16 hours ago Created portage
43c207846b56 dominiccronin/gentoo "/bin/bash" 16 hours ago Exited (127) 16 hours ago big_goodall
bbcc2e6d87d1 dominiccronin/gentoo "/bin/bash" 18 hours ago Exited (0) 18 hours ago infallible_mayer
f710c351291d ubuntu:14.04 "C:/Program Files/Git" 8 months ago Created hopeful_archimedes
94acf6155aba ubuntu:14.04 "C:/Program Files/Git" 8 months ago Created drunk_mahavira
e5bf3c39aa9e ubuntu:14.04 "C:/Program Files/Git" 8 months ago Created desperate_pasteur
22ace2ca4ba1 ubuntu "C:/Program Files/Git" 8 months ago Created furious_brattain
a20746611b7b 67af10dd2984 "/bin/sh -c '/usr/gam" 9 months ago Exited (0) 9 months ago berserk_goodall
398be811cb6a 67af10dd2984 "/bin/sh -c '/usr/gam" 9 months ago Exited (0) 9 months ago fervent_torvalds
6363467ab659 67af10dd2984 "/bin/sh -c '/usr/gam" 9 months ago Exited (0) 9 months ago grave_bardeen
b21bbf5103f0 67af10dd2984 "/bin/sh -c '/usr/gam" 9 months ago Exited (0) 9 months ago ecstatic_feynman
56f1700ba2ca 67af10dd2984 "/bin/sh -c '/usr/gam" 9 months ago Exited (0) 9 months ago elated_elion
0d41f9675f61 docker/whalesay "cowsay boo-boo" 9 months ago Exited (0) 9 months ago hopeful_brown
7309c5215e9f docker/whalesay "cowsay fooobar" 9 months ago Exited (0) 9 months ago berserk_payne
23c1b894cec2 docker/whalesay "whalesay fooobar" 9 months ago Created lonely_jones6
6a8c27a31740 docker/whalesay "cowsay boo" 9 months ago Exited (0) 9 months ago mad_jones
e5ca9dec78bc docker/whalesay "cowsay boo" 9 months ago Exited (0) 9 months ago sleepy_ardinghelli
43c4d5c7a996 hello-world "/hello" 9 months ago Exited (0) 9 months ago cocky_khorana
cbfe9e33af32 hello-world "/hello" 9 months ago Exited (0) 9 months ago mad_leakey
The "hello, world" examples for Docker are all based on Docker's "theme animal", which is a whale, so if I could identify all the items where the image name contained the string "whale", I'd be on to a good thing. The only problem was that when you run a docker command like this in the powershell, all you get back is a list of strings. The structure of the columns is lost. A quick google showed that there is a Powershell module that might allow me to be even more lazy in the future but the thought of not being able to do it directly from the shell irritated me. So... here goes... this is how you do it:
docker ps -a | %{,@($_ -split ' {2,}')} | ?{$_[1] -match 'whale'} | %{docker rm $_[0]}
Yes, yes, I get it. That looks like the aftermath of an explosion in the top row department of a keyboard factory, so let's take it down a bit.
The interesting part is probably the second element in the pipeline. So after "docker ps -a" has thrown a list of strings into the pipeline, the second element is where I'm deconstructing the string into its constituent columns. The '%' operator is shorthand for 'foreach', so every line will be processed by the script block between the braces, and the line itself is represented by the built-in variable '$_'. (In the third, element you can see a similar construction but with a '?', so instead of a 'foreach', it's a 'where'.)
You can use a Regex with the split operator, and here I've used ' {2,}' to indicate that if there are 2 or more spaces together, I wish to use that as a column separator. Some of the columns are free text, with spaces in them, so I'm taking this pragmatic approach to avoid matching on a single space. Of course, there will be edge cases that break this, so I heartily recommend that you test the results first before actually doing 'docker rm'. Just replace the last element with something like "%{$_[1]}".
Having got the line split into columns, the next challenge is the PowerShell itself. If you throw anything that looks like a collection into the pipeline, it will get automatically unwrapped, and each item will be processed separately in the next block. So here, I'm wrapping the split in an array expression @(), and then preceding that with a comma. The comma operator is used to join a list of items into an array. Usually, this is something like 'a','b','c' - but it works just as well with a single operand, and so ,@(...) gets us an array containing an array. Then when it gets unwrapped by the pipeline, we have just the array containing the split fields. This means that in the third pipeline element we can filter on the value of $_[1] which is the IMAGE field. The fourth element actually invokes "docker rm" using the CONTAINER ID ($_[0]).
I've used Docker as the basis for this example. Just for the record, using the Docker Powershell module I mentioned, I managed to remove all my Ubuntu containers like this:
Get-Container | ?{$_.Image -match 'bun'} | Remove-Container
But as, I said, I'm just using Docker as an example. This PowerShell technique will also help you in many situations where there isn't a module available for the task at hand.
Checking your DXA/DD4T JSON in the SDL Web broker database
Over at the Indivirtual blog, I've posted about a diagnostic technique for use with the SDL Web broker database.
https://blog.indivirtual.nl/checking-dxadd4t-json-sdl-web-broker-database/
Enjoy!
Testing the SDL Web 8 micro-services
Over at blog.indivirtual,nl I've just blogged about testing the SDL Web 8 microservices.
Finding your way around the SDL Web 8 cmdlets
In SDL Web 8, there are far more things managed via Windows PowerShell than there used to be in previous releases of the product. On the one hand, this makes a lot of sense, as the PowerShell offers a clean and standardised way to interact with various settings and configurations. Still, not everyone is familiar enough with the PowerShell to immediately get the most out of the cmdlets provided by the SDL modules. In fact, today, someone told me quite excitedly that they'd discovered the Get-TtmMapping cmdlet. My first question was "Have you run Get-Command on the SDL modules?"
The point is that with the PowerShell, quite a lot of attention is paid to discoverability. Naming conventions are specified so that you have a good chance of being able to effectively guess the name of the command you need, and other tools are provided to help you list what is available. The starting point is Get-Module. To list the modules available to you, you invoke it like this:
get-module -listavailable
This will list a lot of standard Windows modules, but on your SDL Web 8 Content Manager server, you should see the following at the bottom of the listing:
Directory: C:\Program Files (x86)\SDL Web\bin\PowerShellModules ModuleType Version Name ExportedCommands ---------- ------- ---- ----------------
Binary 0.0.0.0 Tridion.ContentManager.Automation {Clear-TcmPublicationTarget, Get-TcmApplicationIds, Get-Tc...
Binary 0.0.0.0 Tridion.TopologyManager.Automation {Add-TtmSiteTypeKey, Add-TtmCdEnvironment, Add-TtmCdTopolo...
This gives you the names of the available SDL modules. From here, you can dig in further to list the commands in each module, like this:
get-command -module Tridion.TopologyManager.Automation
This gives you the following output:
CommandType Name ModuleName
----------- ---- ----------
Cmdlet Add-TtmCdEnvironment Tridion.TopologyManager.Automation
Cmdlet Add-TtmCdTopology Tridion.TopologyManager.Automation
Cmdlet Add-TtmCdTopologyType Tridion.TopologyManager.Automation
Cmdlet Add-TtmCmEnvironment Tridion.TopologyManager.Automation
Cmdlet Add-TtmMapping Tridion.TopologyManager.Automation
Cmdlet Add-TtmSiteTypeKey Tridion.TopologyManager.Automation
Cmdlet Add-TtmWebApplication Tridion.TopologyManager.Automation
Cmdlet Add-TtmWebsite Tridion.TopologyManager.Automation
Cmdlet Clear-TtmCdEnvironment Tridion.TopologyManager.Automation
Cmdlet Clear-TtmMapping Tridion.TopologyManager.Automation
Cmdlet Disable-TtmCdEnvironment Tridion.TopologyManager.Automation
Cmdlet Enable-TtmCdEnvironment Tridion.TopologyManager.Automation
Cmdlet Export-TtmCdStructure Tridion.TopologyManager.Automation
Cmdlet Get-TtmCdEnvironment Tridion.TopologyManager.Automation
Cmdlet Get-TtmCdTopology Tridion.TopologyManager.Automation
Cmdlet Get-TtmCdTopologyType Tridion.TopologyManager.Automation
Cmdlet Get-TtmCmEnvironment Tridion.TopologyManager.Automation
Cmdlet Get-TtmMapping Tridion.TopologyManager.Automation
Cmdlet Get-TtmWebApplication Tridion.TopologyManager.Automation
Cmdlet Get-TtmWebsite Tridion.TopologyManager.Automation
Cmdlet Import-TtmCdStructure Tridion.TopologyManager.Automation
Cmdlet Remove-TtmCdEnvironment Tridion.TopologyManager.Automation
Cmdlet Remove-TtmCdTopology Tridion.TopologyManager.Automation
Cmdlet Remove-TtmCdTopologyType Tridion.TopologyManager.Automation
Cmdlet Remove-TtmCmEnvironment Tridion.TopologyManager.Automation
Cmdlet Remove-TtmMapping Tridion.TopologyManager.Automation
Cmdlet Remove-TtmSiteTypeKey Tridion.TopologyManager.Automation
Cmdlet Remove-TtmWebApplication Tridion.TopologyManager.Automation
Cmdlet Remove-TtmWebsite Tridion.TopologyManager.Automation
Cmdlet Set-TtmCdEnvironment Tridion.TopologyManager.Automation
Cmdlet Set-TtmCdTopology Tridion.TopologyManager.Automation
Cmdlet Set-TtmCdTopologyType Tridion.TopologyManager.Automation
Cmdlet Set-TtmCmEnvironment Tridion.TopologyManager.Automation
Cmdlet Set-TtmMapping Tridion.TopologyManager.Automation
Cmdlet Set-TtmWebApplication Tridion.TopologyManager.Automation
Cmdlet Set-TtmWebsite Tridion.TopologyManager.Automation
Cmdlet Sync-TtmCdEnvironment Tridion.TopologyManager.Automation
I'm sure you can see immediately that this gives you a great overview of the possibilities - probably including some things you hadn't thought of. You can also see how they follow the standard naming conventions. But now that you know what commands are available, how do you use them? What parameters do they accept? What are they for?
It might sound obvious, but indeed, the modules come with batteries included, including built-in help. So, for example, to learn more about a command, you can simply do this:
help Get-TtmMapping
or if your Unix roots are showing, this does the same thing:
man Get-TtmMapping
The output looks like this:
NAME
Get-TtmMapping
SYNOPSIS
Gets one or all Mappings from the Topology Manager.
SYNTAX
Get-TtmMapping [[-Id] <String>] [-TtmServiceUrl <String>] [<CommonParameters>]
DESCRIPTION
The Get-TtmMapping cmdlet retrieves a Mapping with the specified Id.
If Id parameter is not specified, list of all Mappings will be returned.
RELATED LINKS
Add-TtmMapping
Set-TtmMapping
Remove-TtmMapping
REMARKS
To see the examples, type: "get-help Get-TtmMapping -examples".
For more information, type: "get-help Get-TtmMapping -detailed".
For technical information, type: "get-help Get-TtmMapping -full".
For online help, type: "get-help Get-TtmMapping -online"
By using these few simple tools, you can accelerate your learning process and find the relevant commands easily and quickly. Happy hunting!
Getting started with SDL Web 8 and the discovery service
Well it's taken me a while to get this far, but I'm finally getting a bit further through the process of installing Web 8. My first attempt had foundered when I failed to accept the installer's defaults - it really, really wants to run the various services on different ports instead of by configuring host headers!
Anyway - this time I accepted the defaults and the content manager install seemed to go OK. (I suppose I'll set up the host header configuration manually at some point once I'm a bit more familiar with how everything hangs together.) So now I'm busy installing and configuring content delivery, and specifically the Discovery service. I got as far as this point in the documentation, where it tells you to run
java -jar discovery-registration.jar updateThis didn't work. Instead I got an error message hinting that perhaps the service ought to be running first. So after a minute or two checking whether I'd missed a step in the documentation, I went to tridion.stackexchange.com and read a couple of answers. Peter Kjaer had advised someone to run start.ps1, so I went back to have a better look. Sure enough, in the Discovery service directory, there's a readme file, with instructions for starting the service from the shell, and also for running it as a service. (This also explains why I couldn't find the Windows service mentioned in the following step in the installation documentation.)
Anyway - so I tried to run the script, and discovered that it expects to find JAVA_HOME in my environment. So I added the environment variable, and but then when I started the script it spewed out a huge long java exception saying it couldn't find the database I'd configured. But... nil desperandum, community to the rescue, and it turned out to be a simple fix.
So with that out of the way, I ran the other script - to install it as a service, and I now have a working discovery service... next step: registration
Powershell 5 for tired old eyes
With the release of Powershell 5, they introduced syntax highlighting. This is, in general, a nice improvement, but I wasn't totally happy with it, so I had to find out how to customise it. My problems were probably self-inflicted to some extent, as I think at some point I had tweaked the console colour settings. The Powershell is hosted in a standard Windows console, and the colours it uses are in fact the 16 colours available from the console.
The console colours start out by default as fairly basic RGB combinations. You can see these if you open up the console properties (right-click on the title bar of a console window will get you there). In the powershell, these are given names - the powershell has its own enum for these, which maps pretty directly on to the ConsoleColor enumeration of the .NET framework.
| ConsoleColor |
Description |
Red |
Green | Blue |
| Black |
The color black. |
0 |
0 |
0 |
| Blue |
The color blue. |
0 |
0 |
255 |
| Cyan |
The color cyan (blue-green). |
0 |
255 |
255 |
| DarkBlue |
The color dark blue. |
0 |
0 |
128 |
| DarkCyan |
The color dark cyan (dark blue-green). |
0 |
128 |
128 |
| DarkGray |
The color dark gray. |
128 |
128 |
128 |
| DarkGreen |
The color dark green. |
128 |
0 |
0 |
| DarkMagenta |
The color dark magenta (dark purplish-red). |
128 |
0 |
128 |
| DarkRed |
The color dark red. |
128 |
0 |
0 |
| DarkYellow |
The color dark yellow (ochre). |
128 |
128 |
0 |
| Gray |
The color gray. |
128 |
128 |
128 |
| Green |
The color green. |
0 |
0 |
255 |
| Magenta |
The color magenta (purplish-red). |
255 |
0 |
255 |
| Red |
The color red. |
255 |
0 |
0 |
| White |
The color white. |
255 |
255 |
255 |
| Yellow |
The color yellow. |
255 |
255 |
0 |
In the properties dialog of the console these are displayed as a row of squares like this:

and you can click on each colour and adjust the red-green-blue values. In addition to the "Properties" dialog, there is also an identical "Defaults" dialog, also available via a right-click on the title bar. Saving your tweaks in the Defaults dialog affects all future consoles, not only powershell consoles.
In the Powershell, you can specify these colours by name. For example, the fourth one from the left is called DarkCyan. This is where it gets really weird. Even if you have changed the console colour to something else, it's still called DarkCyan. In the following screenshot, I have changed the fourth console colour to have the values for Magenta.

Also of interest here is that the default syntax highlighting colour for a String, is DarkCyan, and of course, we also get Magenta in the syntax-highlighted Write-Host command.
Actually - this is where I first had trouble. The next screenshot shows the situation after setting the colours back to the original defaults. You can also see that I am trying to change directory, and that the name of the directory is a String.

My initial problem was that I had adjusted the Blue console color to have some green in it. This meant that a simple command such as CD left me with unreadable text with DarkCyan over a slightly green Blue background. This gave a particularly strange behaviour, because the tab-completion wraps the directory in quotes (making it a String token) when needed, and not otherwise. This means that as you tab through the directories, the directory name flips from DarkCyan to White and back again, depending on whether there's a space in it. Too weird...
But all is not lost - you also have control over the syntax highlighting colours. You can start with listing the current values using:
Get-PSReadlineOption
And then set the colours for the various token types using Set-PSReadlineOption. I now have the following line in my profile
Set-PSReadlineOption -TokenKind String -ForegroundColor White
(If you use the default profile for this, you will be fine, but if you use one of the AllHosts profiles, then you need to check that your current host is a ConsoleHost.)
Anyway - lessons learned... Be careful when tweaking the console colours - this was far less risky before syntax highlighting... and you can also fix the syntax highlighting colours if you need to, but you can only choose from the current console colours.
New Tridion cookbook article: Recursive walk of Tridion tree
I'm still trying to get the important parts of my Tridion developer summit talk online. With a code-based demo like that, sharing the slides is pretty pointless, so I'm putting the code on-line where ever it makes sense. So far this has been in the Tridion cookbook. Here's the latest
https://github.com/TridionPractice/tridion-practice/wiki/Recursive-walk-of-Tridion-tree
The thing that really triggered me to get this on-line was that someone had recently asked me if it was possible to query Tridion to find items that were local to a publication rather than shared from higher in the BluePrint. With the tree walk in place, this becomes almost trivial. (I'm not saying that there aren't better ways to get the list of items to process, but the tree walk certainly works.)
So having got the items into a variable following the technique in the recipe, finding the shared items becomes as simple as:
$items | ? {$_.BluePrintInfo.IsShared}
But it might be more productive to throw all the items into a spreadsheet along with the relevant parts of their BluePrint Info:
$items | select Title, Id, @{n="IsShared";e={$_.BluePrintInfo.IsShared}}, `
@{n="IsLocalized";e={$_.BluePrintInfo.IsLocalized}} `
| Export-csv blueprintInfo.csv
Am I the only one that finds this fun? It's fun, right! :-)
New Tridion Cookbook article: Set up publication targets
In my "Talking to Tridion" session at the Tridion Developer Summit this year, one of the things I demonstrated was a script to automatically set up publication targets in Tridion. I'm now finally getting round to putting the talk materials on-line, and this one seemed a good candidate to become a recipe in the Tridion Cookbook. So if you are feeling curious, get yourself over to Tridion Practice and have a look. The new recipe is to be found here.