Dominic Cronin's weblog
Room for a little YAGNI in the DXA :-)
I wouldn't usually call out open source code in a blog post, but honestly, this made me Laugh Out Loud in the office yesterday. I'd ended up poking around in the part of the Tridion Digital Experience Manager framework (DXA) that deals with media items. Just to be clear, the media items in question would usually be either binaries that have some role in displaying your web site, or in this case, more specifically, downloads such as a PDF or whatever. The thing that made me laugh was in a function called getFriendlyFileSize(). A common use case for this would be to display a file size next to your download link so the visitor knows that they can download the PDF fairly quickly, or that maybe they'd better wait until they're on the Wifi before attempting that 10GB ISO file.
getFriendlyFileSize() converts a raw number of bytes into something like 13MB, 7KB, or 5GB. What made me laugh was the fact that the author has also very helpfully included support not only for GigaBytes, but also TeraBytes, PetaBytes and ExaBytes.
Sitting in my office right now, I'm getting about "140 down" from Speedtest. That is to say, my download speed from the Internet is about 140 Mbps, which works out in practice that if I want to grab the latest Centos-with-all-the-bells-and-whistles.ISO (let's say 10GB) it'll take me about 10 minutes. Let's say I want to scale that up to 10PB, then we're talking about 400 years or so, which somewhat exceeds the longest web server uptime known to mankind by an order of magnitude and then some.
Well maybe this is just old-fashioned thinking, but I'm inclined to think we don't need friendly Exabyte file sizes for website media downloads just yet. In the words of the old Extreme Programming mantra, "You ain't gonna need it". (YAGNI)
I'm not here to take a rise out of the hard-working hackers that contribute so much to us all. Really. I can't say that strongly enough. It made me laugh out loud, that's all.
Getting SSH working on WSL
Or on longhand: getting the Secure Shell working on the Windows Subsystem for Linux.
I've run a Unix command line on my Windows systems for years using Cygwin. I'm not one of those Unix nerds that can't function in a native Windows world, but there was always one particular use case that Windows was spectacularly poor in. If you wanted to connect to *nix systems, the obvious way to do this was via the Secure Shell (SSH) and Windows just didn't have an SSH client. Full stop. Nothing, nada, etc. Windows had its own mechanisms for connecting securely to.... another Windows box. If you wanted to connect to something that wasn't Windows.... well who'd want to do that?
Those of us that did installed Cygwin. This was an implementation of a *nix kernel in a DLL, and a bunch of the standard utilities built to use it. You could (and still can) do pretty much anything: if you couldn't search a file system without grep, Cygwin made it OK for you. I didn't use many of the utilities apart from occasionally Ghostscript to manipulate PDFs, but I used SSH every day.
Eventually Microsoft wised up and realised that open source wasn't the enemy. Linux was cool, and even Microsofties could learn to love it. So they implemented the Linux kernel as a Windows driver and called it the Windows Subsystem for Linux. They first teamed up with Ubuntu to get the user space stuff running, and then later with Suse and Debian, so you've got a fair choice if you're fussy about your distros.
And still - the killer use case is opening up a secure shell session to a Linux box. This is why we want WSL. So it's a bit rubbish when you discover that the standard way of logging in to such a remote session doesn't work. I'm talking about public key authentication. The basic idea is that you have two files holding the two parts f a public/private key pair. One lives on the server, and the other on the client. With this setup, you just make the connection and you're logged in. In order to keep this secure, the standard SSH client software insists that they key file is secured so that it's private to you. If anyone else can read it, the software will just refuse to play ball.
This is all well and good as long as you can set the security up to do that, but under WSL, in its out of the box configuration, you can't. This has been a source of great irritation to me, and I have now figured out the solution for the second time, having failed to write a note-to-self blog post the last time. This time, I'm writing it. See?
The bottom line is that you need to have the WSL enable file system metadata so that you can override the security settings you need to. Here's an article explaining why, and here's one explaining how.
TL;DR
From in your WSL shell create "/etc/wsl.conf". You'll probably need to sudo in to vi to do this or you won't be able to save it. In the file, add the following:
[automount] options="metadata"
With this in place, the next time you start the shell, metadata will be enabled, and you'll be able to "chmod 700" your key files to your heart's content.
Using environment variables to configure the Tridion microservices
Within a day of posting this, Peter Kjaer informed me that the microservices already support environment variables, so this entire blog post is pointless. So my life just got simpler, but it cost me a blog post to find out. Oh well. I'm currently trying to decide whether to delete the post entirely or work it into something useful. In the meantime at least be aware that it's pointless! :-) Anyway - thanks Peter.
When setting up a Tridion content delivery infrastructure, one of the most important considerations is how you are going to manage all the configuration values. The microservices have configuration files that look very similar to those we're familiar with from versions of Tridion going back to R5. Fairly recently, (in 8.5, I think) they acquired a "new trick", which is that you can put replacement tokens in the files, and these will be filled in with values that you can pass as JVM parameters when starting up your java process. Here's an example taken from cd_discovery_conf.xml
<ConfigRepository ServiceUri="${discoveryurl:-http://localhost:8082/discovery.svc}"
ConnectionTimeout="10000"
CacheEnabled="true"
CacheExpirationDuration="600"
ServiceMonitorPollDuration="10"
ClientId="registration"
ClientSecret="encrypted:HzfQh9wYwAKShDxCm4DnnBnysAz9PtbDMFXMbPszSVY="
TokenServiceUrl="${tokenurl:-http://localhost:8082/token.svc}">
Here you can see the tokens "discoveryurl" and "tokenurl" delimited from the surrounding text with ${} and followed by default values after the :- symbol.
This is really handy if you are doing any kind of managed provisioning where the settings have to come from some external source. One word of warning, though. If you are setting up your system by hand and intending to maintain it that way, it's most likely a really bad idea to use this technique. In particular, if you are going to install the services under Windows, you'll find that the JVM parameters are stored in a deeply obscure part of the registry. More to the point, you really don't want two versions of the truth, and if you have to look every time to figure out whether tokenurl is coming from the default in your config or from deep underground, I don't hold out much hope for your continued sanity if you ever have to troubleshoot the thing.
That said, if you do want to provision these values externally, this is the way to go. Or at least, in general, it's what you want, but personally I'm not really too happy with the fact that you have to use JVM parameters for this. I've recently been setting up a dockerised system, and I found myself wishing that I could use environment variables instead. That's partly because this is a natural idiom with docker. Docker doesn't care what you run in a container, and has absolutely no notion of a JVM parameter. On the other hand, Docker knows all about environment variables, and provides full support for passing them in when you start the container. On the command line, you can do this with something like:
> docker run -it -e dbtype=MSSQL -e dbclass=com.microsoft.sqlserver.jdbc.SQLServerDataSource -e dbhost=mssql -e dbport=1433 -e dbname=Tridion_Disc
-e discoveryurl=http://localhost:8082/discovery.svc -e tokenurl=http://localhost:8082/token.svc discovery bash
I'm just illustrating how you'd pass command-line environment arguments, so don't pay too much attention to anything else here, and of course, even if you had a container that could run your service, this wouldn't work. It's not very much less ugly than constructing a huge set of command parameters for your start.sh and passing them as a command array. But bear with me; I still don't want to construct that command array, and there are nicer ways of passing in the environment variables. For example, here's how they might look in a docker-compose.yaml file (Please just assume that any YAML I post is accompanied by a ritual hawk and spit. A curse be on YAML and it's benighted followers.)
environment:
- dbtype=MSSQL
- dbclass=com.microsoft.sqlserver.jdbc.SQLServerDataSource
- dbhost=mssql
- dbport=1433
- dbname=Tridion_Discovery
- dbuser=TridionBrokerUser
- dbpassword=Tridion1
- discoveryurl=http://localhost:8082/discovery.svc
- tokenurl=http://localhost:8082/token.svc
This is much more readable and manageable. In practice, rather than docker-compose, it's quite likely that you'll be using some more advanced orchestration tools, perhaps wrapped up in some nice cloudy management system. In any of these environments, you'll find good support for passing in some neatly arranged environment variables. (OK - it will probably degenerate to YAML at some point, but let's leave that aside for now.)
Out of the box, the Tridion services are started with a bash script "start.sh" that's to be found in the bin directory of your service. I didn't want to mess with this: any future updates would then be a cause for much fiddling and cursing. On top of that, I wanted something I could generically apply to all the services. My approach looks like this:
#!/bin/bash
# vim: set fileformat=unix
scriptArgs=""
tcdenvMatcher='^tcdconf_([^=]*)=(.*)'
for tcdenv in $(printenv); do
if [[ $tcdenv =~ $tcdenvMatcher ]]; then
scriptArgs="$scriptArgs -D${BASH_REMATCH[1]}=${BASH_REMATCH[2]}"
fi
done
script_path="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null && pwd )"
$script_path/start.sh $scriptArgs
(I'm sticking with the docker-compose example to illustrate this. In fact, with docker-compose, you'd also need to script some dependency-management between the various services, which is why you'd probably prefer to use a proper orchestration framework.)
The script is called "startFromEnv.sh". When I create my docker containers, I drop this into the bin folder right next to start.sh. When I start the container, the command becomes something like this, (but YMMV depending on how you build your images).
command: "/Discovery/bin/startFromEnv.sh"
instead of:
command: "/Discovery/bin/start.sh"
And the environment variables get some prefixes, so the relevant section of the setup looks like this:
environment: - tcdconf_dbtype=MSSQL - tcdconf_dbclass=com.microsoft.sqlserver.jdbc.SQLServerDataSource - tcdconf_dbhost=mssql - tcdconf_dbport=1433 - tcdconf_dbname=Tridion_Discovery - tcdconf_dbuser=TridionBrokerUser - tcdconf_dbpassword=Tridion1 - tcdconf_discoveryurl=http://localhost:8082/discovery.svc - tcdconf_tokenurl=http://localhost:8082/token.svc
The script is written in bash, as evidenced by the hashbang line at the top. (Immediately after is a vim modeline that you can ignore or delete unless you happen to be using an editor that respects such things and you are working on a Windows system. I've left it as a reminder that the line endings in the file do need to be unix-style.)
The rest of the script simply(!) loops through the environment variables that are prefixed with "tcdconf_" and converts them to -D arguments which it then passes on to script.sh (which it looks for in the same directory as itself).
I'm still experimenting, but for now I'm assuming that this approach has improved my life. Please do let me know if it improves yours. :-)
If you think the script is ugly, apparently this is a design goal of bash, so don't worry about it. At least it's not YAML (hack, spit!)
Using the Tridion PowerShell module in a restricted environment
At some point, pretty much every Tridion specialist is going to want to make use of Peter Kjaer's Tridion Core Service Powershell modules. The modules come with batteries included, and if you look at the latest version, you'll see that the modules are available from the PowerShell gallery, and therefore a simple install via Install-Module should "just work".
Most of us spend a lot of our time on computers that are behind a corporate firewall, and on which the operating system is managed for us by people whose main focus is on not allowing us to break anything. I recently found myself trying to install the modules on a system with an older version of PowerShell where Install-Module wasn't available. The solution for this is usually to install the PowerShellGet module which makes Install-Module available to you. In this particular environment, I knew that various other difficulties existed, notably with the way the PowerShell module path is managed. Installing a module would first require a solution to the problem of installing modules. In the past, I'd made a custom version of the Tridion module as a workaround, but now I was trying to get back to a clean copy of the latest, greatest version. Hacking things by hand would defeat my purpose.
It turned out that I was able to clone the GIT repository, so I had the folder structure on disk. (Failing that I could have tried downloading a Zip file from GitHub.)
Normally, you install your modules in a location on the Module Path of your PowerShell, and the commonest of these locations is the WindowsPowerShell folder in your Documents folder. (There are other locations, and you can check these with "gc Env:\PSModulePath".) As I've mentioned, in this case, using the normal Module Path mechanism was problematic, so I looked a little further. It turned out the solution was much simpler than I had feared. You can simply load a module by specifying its location when you call ImportModule. I made sure that the tridion-powershell-modules folder I'd got from GIT was in a known location relative to the script file from which I wanted to invoke it, and then called Import-Module using the location of Tridion-CoreService.psd1
$scriptLocation = Split-Path ((Get-Variable MyInvocation -Scope 0).Value).MyCommand.Path
import-module $scriptLocation\..\tridion-powershell-modules\CoreService\Tridion-CoreService.psd1
Getting the script location from the built-in MyInvocation variable is ugly, but pretty much standard PowerShell. Anyway - this works, and I now have a strategy for setting up my scripts to use the latest version of the core service module. Obviously, if you want the Alchemy or Content Delivery module, a similar technique ought to work.
Getting gvim to work from the Ubuntu on Windows bash prompt
Just lately I've been tinkering a bit more with Linux-y things, among which trying to get to grips with a bit of bash scripting. As my main work environment is a Windows 10 system, the obvious place for such tinkering is in the Windows Sub-System for Linux (WSSL or WSL depending on whose abbreviation you favour). In any case, the bash prompt in Windows.
Generally, WSSL works rather well, <rant>my main proviso there being the really unhelpful problems with permissions. I get it... it's probably a really nasty job to fix it, but really!.... for chmod to be broken is just wrong! More to the point, it means I can't use a private key for ssh logins to other systems. Maybe I'll go back to cygwin after all.</rant>
Anyway, today's problem was rather more tractable. I wanted to edit a bash script using gvim. My first attempt was just to open it from the bash prompt:
dominic@DOMINIC:/mnt/d/code/bash$ gvim foo.sh
E233: cannot open display
Press ENTER or type command to continue
Yeah OK, that then falls back to a standard vim session in the terminal, but if that's what I'd wanted, I wouldn't have typed 'gvim'.
It turns out that there's a version of gvim in the Ubuntu user-space stuff that comes with WSSL. When you type gvim at the prompt, it finds /usr/bin/gvim in the PATH, and tries to open that.
Nil desperandum
dominic@DOMINIC:/mnt/d/code/bash$ file /usr/bin/gvim
/usr/bin/gvim: symbolic link to `/etc/alternatives/gvim'
dominic@DOMINIC:/mnt/d/code/bash$ sudo unlink /usr/bin/gvim
dominic@DOMINIC:/mnt/d/code/bash$ sudo ln -s /mnt/c/Program\ Files\ \(x86\)/vim/vim80/gvim.exe /usr/bin/gvim
After that it worked like a treat. Maybe the other way to go would be to see if you can get an XWindows server running on WSSL, but this got me up and running without having to get into even more faff with copies of rc files and whatnot.
Which device size are you looking at in Bootstrap 3?
If you work on websites these days, you've probably come across Bootstrap. It's a HTML/CSS/JS framework for producing responsive user interfaces for web sites. One of the things it does for you is manage a grid system in which your page has 12 columns, and you get to decide how many columns each element in your page should occupy. You do this by putting classes on your HTML elements that look something like "col-xs-4", which means "allow this element to occupy 4 columns on an extra small device. In Bootstrap 3, there are four device sizes: Extra small, Small, Medium and Large. If you specify different amounts of columns for the different devices, then as you resize your device (usually in the responsive emulator of your browser), you'll see the various blocks sliding under each other as things get smaller.
When you're doing this, it's quite handy to know which device size Bootstrap thinks it's got at any given moment. I wanted to know this, so after a bit of fiddling, I came up with the following:
<span class="hidden-sm hidden-md hidden-lg">XS</span> <span class="hidden-xs hidden-md hidden-lg">SM</span> <span class="hidden-xs hidden-sm hidden-lg">MD</span> <span class="hidden-xs hidden-sm hidden-md">LG</span>
With this pasted somewhere handy in the footer or header, you can monitor whether the changing shape of your page is in line with your expectations for a given device size. You'll see the letters that refer to the size of device you're looking at. Obviously, it's something you'd want to remove before you actually ship code.
A couple of provisos:
- This is for Bootstrap 3. Bootstrap 4 is different enough that you might even see it as a different framework. The equivalent technique would be with "display" classes that typically begin with "d-".
- You might be able to get this a bit tighter. The device sizes are a hierarchy, so maybe some of my classes aren't necessary. I stopped when it worked. Life's too short!
- Bootstrap is very customisable, so YMMV
Getting started with Insomnia as a Tridion content delivery client
Today I ran across Insomnia, which is a generic development/test client for RESTful HTTP services much along the same lines as Postman. The latter is pretty well established, but it's a paid product, and Insomnia seems at first sight to be more or less a clone, but open source and free. (That said, Postman is free to most people, and Insomnia has paid-for plugins. Everyone's got to eat, right?)
It will hardly be a surprise to the reader that my interest in this is in the context of Tridion's content delivery APIs. To be honest I haven't really spent much time getting to know Postman, preferring to make use of simple Powershell scripts for purposes such as validating that the services are running and that authentication is working. While there's much to be said for a scripted approach, I've always had niggling doubts that perhaps I'd find my way around the data a bit more easily with a GUI client. Coming across Insomnia today is my opportunity to find out whether this is so.
I started by downloading and installing the Windows version (like Postman, it's also available for Linux and Mac). So far, I've got as far as making a simple query against my content service. To do this, you have to figure your way through the somewhat arcane details of getting an OAuth token. The services on my Tridion research server are not secured in any meaningful way, but OAuth is still "switched on. That is to say, I have the out-of-the-box user accounts configured in my discovery service's cd_ambient_conf.xml along with the out-of-the-box passwords. So obviously, don't do this at home children, but hey - it's my research rig, not a production server. This being the case, I'm not giving much away by sharing the following:
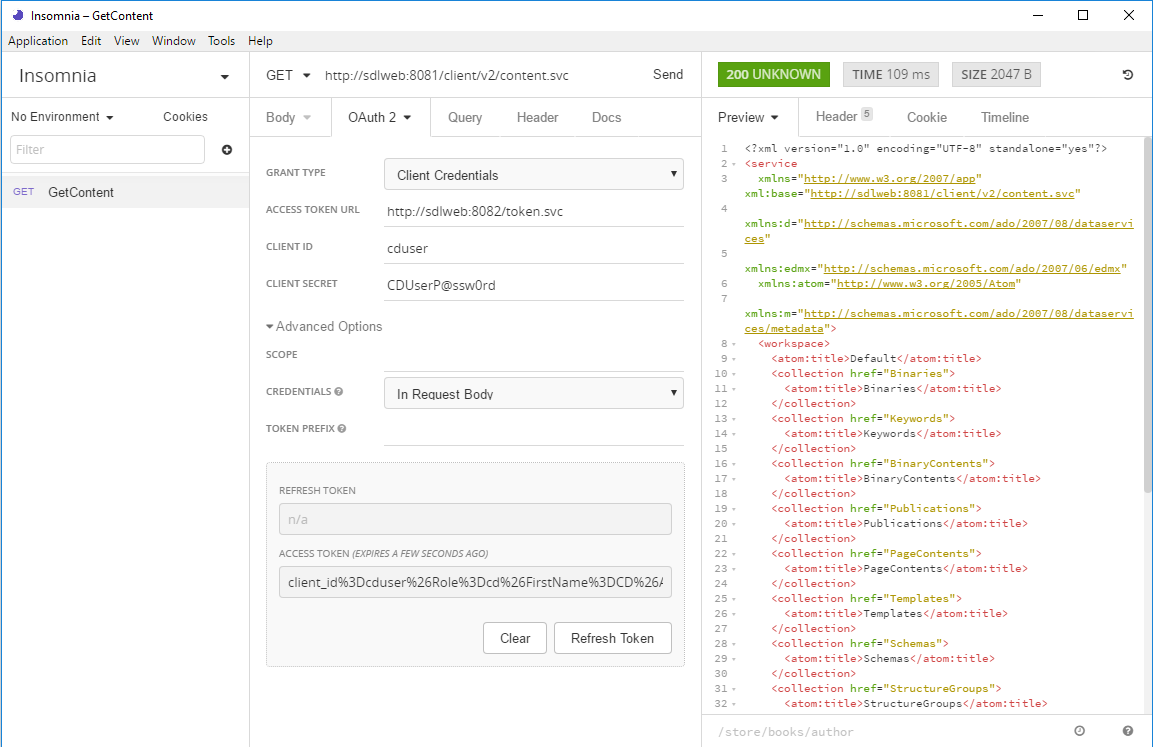
What you can see here is that my Tridion image is running at "sdlweb", so I'm issuing a GET against http://sdlweb:8081/client/v2/content.svc. Insomnia has support for variables, so I imagine you could use one for the hostname if you want to keep your tests generic.
You can also see that I've got the authentication tab open and have selected OAuth2. The first thing you need to do is select Client Credentials for the grant type. With this choice, you only need to fill in the client id and secret. (Obviously these need to match your actual security settings, and of course, you haven't left these at their defaults... right!?)
The only thing that made me scratch my head for a short moment was that when I tried with just those details, it didn't work, and I got a 400 status back. That's HTTP for "Bad request", so I went into the Advanced settings to see if there was anything I could change to make the server happier about my manners. It turns out that switching Credentials to "In Request Body" is all you need and as you can see, there's a nice green 200 status displaying, and some data from the service.
Well that's enough to get me started. Please do let me know about your experiences with Insomnia. Especially if you're a Postman maven, let me know how the two stack up against each other.
Connecting to Microsoft SQL Server Developer from Tridion Content Delivery
I've recently been setting up a development image for SDL Web 8.5, and as it's only for use on my development rig, it's fair game to use Microsoft SQL Server Developer edition. It's not supported by SDL, but it's close enough to make it a reasonable risk for my purposes. I got the databases set up and the content manager installed OK, so I moved on to the content delivery stack.
First I hacked together a database test script to make sure I had all the logins correct etc. I've done it this way for years, and you may have seen my blog about it quite a long time ago. Everything seemed fine.
I'd started with the Discovery service, and I'd configured the cd_storage_conf.xml with the relevant database settings I'd just tested. How hard could it be? Except that it didn't work. I got messages in the logs telling me to check my firewall. Doh! Off I went and opened up the firewall ports for my microservices (which I'd forgotten to do) and also 1433 for MSSQL. Still no joy.
Somewhere along the way I'd also disabled loopback checking and double-checked a bunch of other things that can cause trouble. No joy.
I went back to my database test script a few times. It uses a System.Data.SqlClient.SqlConnection to execute a simple command. The connection string specifies '(local)' as the server. I'd had trouble with using '(local)' in the cd_storage_conf.xml in a previous version of Tridion, so I had specified 'localhost' instead, and then when that didn't work, a different name that mapped to the same interface. Still nothing.
The troubling thing was that the test script worked fine. Why was that, when Tridion's java stack had trouble doing the same thing? I should have cottoned on to this way earlier, but eventually I started checking to see if there was actually anything listening on 1433. No there wasn't. Well that helped. And then I started poking around in the network configuration of SQL Server. Sure enough: TCP/IP wasn't enabled. I'm still not sure if this is a Developer edition thing. I seem to recall having come across it before. I'm not the only one. Now that I know the answer, finding a suitable Stack Overflow answer is easy! Maybe I'd had trouble with SQLEXPRESS.
Anyway, at least that explained why my test script worked OK. The SqlConnection client sees '(local)' and is then able to attempt a named pipes or shared memory connection as well as TCP/IP. The java client, on the other hand, doesn't have this repertoire of options and if TCP/IP fails, it's over.
Anyway - now it's fixed. Just time for a quick Note To Self, and on with the rest of my system.
Mashing your scanned JPGs back into one big PDF
It happens more often these days. You get some form sent to you as a PDF. You print it out, and fill it in, and then you want to scan it back in and send it back. For one reason or another, my scanner likes to scan documents to JPEG files: one file per scan. Grr...
In the past, I've used some PDF printer driver or other to solve this problem, but under the water they pretty much all use ghostscript, so why not do it directly. I used to install cygwin on my Windows machines to get access to utilities like this, but these days, Windows embeds a pretty much functional Ubuntu.
So yeah - just directly using ghostscript. How hard can it be? Well it turns out that a bit of Googling leads you to typing some pretty gnarly command lines, especially since I had scanned a 15 page document into 15 separate JPG files. And then Adobe Acrobat didn't understand the resulting document. No good at all. So then I googled further and found this.
It turns out that by installing not only ghostscript but imagemagick, the imagemagick "convert" utility knows how to do exactly what you want, presumably by enlisting the help of ghostscript. So simply by cd'ing to the directory where I had my scans, this...
$ convert *.JPG outputfile.pdf
... did the trick. Pretty neat, huh? Note to self....
System refresh: new architecture for www.dominic.cronin.nl
It's taken a while, and the odd skinned knuckle and a bit of cursing, but I can finally announce that this site is running on...erm.. the other server. Tada! Ta-ta-ta-diddly.... daaahhhh!!!!
Um yeah - I get it. it's not so exciting is it really? The blog's still here, and it's got more or less the same content. It doesn't look any different. Maybe it's a tiny smidgin faster, but even that's more likely to do with the fact that we switched over to an ISP that actually makes use of the glass that runs in to our meter cupboard.
But I'm excited. Just a bit, anyway. Partly because it's taken me months. It needn't have, but it's the usual question of squeezing it into the cracks between all the other things that need to get done in life. That and the fact that I'm an utter cheapskate and I don't want to pay for anything. There's also plenty not to be excited about. As I said, the functionality is exactly as it was. The benefits I get from it are mostly about the ability to do things better going forward.
So what have I done? Well it all started an incredibly long time ago when I started tinkering with docker. I figured that the whole containerisation technology thing had such a lot of potential that I ought at least to run docker on my own server. After all, over the years, I'd always struggled with Plone needing to have a different version of Python than the one available in the current Gentoo ebuilds. I'd attempted a couple of things, including I think an early version of what became LXC, but then along came virtualenv, which made the whole thing moot.
Yeah, well - until I wanted to play with docker for itself. At this point, I just thought I'd install it on my server, and get going, but I immediately discovered, that the old box I was running was 32-bit, and docker is just far too hip to run on anything so old-fashioned. So I needed a new server, and once I'd realised that, that's when the whole thing started. If I was going to have a new server, why didn't I just containerise everything? It's at this point that someone inevitably chips in with a suggestion that if I weren't such a dinosaur, I'd run it on the cloud, wouldn't I? Well yes - sure! But I told you - I'm a cheapskate, and apart from that, I don't want anyone's soul-less reliability messing with my carefully constructed one-nine availability commitment.
Actually I like cloud tech, but frankly, when you look at the micro-budget that supports this site, I'd have spent all my time searching out a super-cheap host, and even then I'd have begrudged it. So my compromise with myself was that I'd build it all very cloudy, and then the world's various public clouds would be my disaster recovery plan. And so it is. If this server dies, I can get it all up in the cloud with a fairly meagre effort. Still not going to two-nines though.
So I went down to my local high street where there's a shop run by these Indian guys. They always have a good choice of "hardly used" ex-business computers. I think I shelled out a couple of hundred Euros, and then I had something with an i5 and enough memory, and a couple of stupidly big disks to make a raid. Anyway - more than enough for a web server - which is just as well, because pretty soon it ends up just being "the server", and it'll get used for all sorts of other things. All the more reason to containerise everything.
I got the thing home, and instead of doing what I've done many times before, and installing Gentoo linux, I poked around a bit on the Internet and found CoreOS. Gentoo is a masochist's delight. I mean - it runs like a sports car, but you have to own a set of spanners. CoreOS, on the other hand, is more or less maintenance free. It's built on Gentoo's build system, so it inherits the sports car mentality of only installing things you are going to use, but then the guys at CoreOS do that, and their idea of "things you are going to use" is basically everything that it takes to get containers up and keep them running, plus exactly nothing else. For the rest, it's designed for cloud use, so you can install it from bare metal to fully working just by writing a configuration file, and it knows how to update itself while running. (It has a separate partition for the new version, and it just switches over.)
So with CoreOS up and running, the next thing was to convert all the moving parts over to Docker containers. As it stands now, I didn't want to change too much of the basics, so I'm running Plone on a Gentoo container. That's way too much masochism though. I'd already been thinking I'd do a fresh one with a more generic out-of-the-box OS, and I've just realised I can pull a pre-built Plone image based on Debian (or Alpine). This gets better and better. And I can run it all up side-by-side in separate containers until I'm ready to flip the switch. Just great! Hmm... maybe my grand master plan was just to get to Plone 5!
The Gentoo container I'm using is based on one created by the Gentoo community, which you can pull from the Docker hub. Once I found this, I thought I was home and dry, but it's not really well-suited to just pulling automatically from a docker file. What they've done is to separate out the portage tree into a separate container. This is smart, because you are unlikely to want the whole of portage in your container for any given purpose that makes you want to run Gentoo. What you do instead is mount the portage data using docker's --volumes-from argument. With it mounted, you can run emerge and install whatever packages you need, and then at runtime you get to run a much slimmer system. Which is great, but it means you have to create and store your own image manually rather than using a dockerfile. (At least, that's how it ended up for a noob like me, once I realised that dockerfile doesn't have an equivalent of --volumes-from.)
My goal was to set up CoreOs to automatically pull the docker images it needed, and run some setup commands. This meant that I'd need to have my personalised Gentoo image available somewhere. Some of the data in there was sensitive, so I went looking for a private Docker registry that I could upload it to. There are plenty of private registries, but most of them aren't free. (If you don't mind the whole world pulling your containers, then free registries abound.) I eventually found https://canister.io/, which suited my needs. That said, my needs aren't much. If I ever need an alternative to canister, I'll probably look at Google Cloud Platform, which isn't free but has a private container registry where you only pay for storage and data egress, at pretty reasonable rates. Or I could just host it myself, but that's maybe too many eggs in the same basket.
Meanwhile, my very next step ought most probably be to get backups sorted out. The "Dockerish" way to do this is to run up yet another dedicated container to deal with just this concern. Then if I want to host it separately, and my backup approach changes, nothing else needs to. Once I have the backups sorted out, it will definitely be worth the while to tidy things up so that I really can just push to the cloud if needs be. The way it's set up now, I could be up and running again very quickly but we're probably talking hours rather than seconds.
I'm really enjoying the flexibility that containerisation gives me, although it's definitely important to get into the right mindset. Being able to build containers that will run on a really generic platform is quite liberating.