Dominic Cronin's weblog
Keylength gotcha when setting up Tridion Access management.
I'm busy setting up Access Management on my Tridion server. There are quite a lot of moving parts, so I'm working step by step and checking as I go. I've got as far as configuring the details of my identity provider, and I'm about to start kicking the tyres properly, but it's not quite working just yet. My "go to" tool for checking something like this is Fiddler: I want to see what traffic is going backwards and forwards between the Access Manager server and the identity provider, if only to see what's in the JSON, but before I can get to that, I can see that I'm getting some 500 errors when the browser calls the /access-management/connect/token endpoint.
In the response, I can see the following:
IDX10630: The 'Microsoft.IdentityModel.Tokens.X509SecurityKey,
KeyId: '604BDFF176DB97F7C6D42CC4E7252C92F69F6A82',
InternalId: '48edf05d-a5da-4c81-98d7-96a4e08da898'.'
for signing cannot be smaller than '2048' bits. KeySize: '1024'.
(Parameter 'key.KeySize')
It says I should check the logs, and sure enough, the same information is there. I'm guessing that it's trying to sign the token using the certificate I've provided. It's using the Microsoft.IdentityModel library - which is probably quite justified in complaining about an insecure key length. Maybe you'll never come across this problem in production work, but I'd just generated the certificate in OpenSSL using the defaults. Close enough for a dev box, I thought, but apparently not.
So - back to OpenSSL and this time, I've specified the key length when generating the keys.
openssl genpkey -out accmanTokenSigning.key -algorithm RSA -pkeyopt rsa_keygen_bits:2048
With the new keys, it's simply a question of generating a new CSR, signing it, and exporting it to pfx format, copying it over to my server, editing the appsettings.json to point at the new file and a quick IISRESET.
It looks like that's now working, and I can get a bit further with familiarising myself with the intricacies of the relationship between Access manager and the identity provider.
With the best will in the world, there's no way Tridion R&D can catch every possible way in which a library from Microsoft that they use decides to be fussy. To be fair to Microsoft, it's fussy in a good way. For end users like me, it's just one more gotcha to look out for.
The main take away from this is "don't doubt yourself". When you're dealing with an unfamiliar system and it doesn't immediately behave as it should, the temptation is to just throw your hands up and assume it's beyond you to get the incantations right. It's black magic, after all, and you don't understand it. So back to the old mantra: look in the logs, look in the other logs, and look in the logs you haven't thought of". In this case, Fiddler got me there pretty quickly - that had been my starting point, because I didn't know if it was Access manager or the Identify provider causing trouble. Even if the HTTP response hadn't said look in the logs, I would have done so fairly soon. There's always more information if you look for it.
Adding an authorization header for the Tridion content service using Fiddler
I've started to experiment with the GraphQL API offered by Tridion Sites 9's Content service. The obvious way to do this is to use the GraphiQL endpoint. On my system I can do this by pointing my browser at http://cd.local:8081/cd/api/graphiql. The only fly in the ointment is that the service expects an OAuth header, so you have to take care of that yourself. The guidance I've seen so far is to use a browser plugin like Requestly to do this, so I duly installed it, and was able to get successful query responses instead of the dreaded 'invalid_grant'. All well and good, but honestly, it's a right faff. Firstly, the plugin itself is clunky, so to open the relevant config window, you're at least several clicks away from sorting out your authorization header, which wouldn't be too bad, but the darned things keep timing out, so you keep having to repeat the procedure. Maybe there's a better plugin, but I figured life's too short. I use Fiddler quite often for faking various scenarios and making test setups work a bit more like they are supposed to in the real world, so why not knock off a quick Fiddler script and be done with it.... I thought!
Actually - it turned out to be a bit fiddly, but I now have it working, so time to share. Usual disclaimers.... it's not very polished. It works for my scenario, and if yours is different you'll have to use the source, Luke.
So - go and open up Fiddler and head to the FiddlerScript button or go to the Rules->CustomiseRules menu option. Once you have a script editing screen in view, you should be able to find the function OnBeforeRequest(oSession: Session). Inside this function, paste in the following code and fix it up to meet your own bizarre preferences:
if (oSession.uriContains("http://cd.local:8081/cd/api")) {
var client_id = "cduser";
var client_secret = 'CDUserP@ssw0rd';
var strBody = "client_id=$client_id&client_secret=$client_secret&grant_type=client_credentials&resources=%2F".replace("$client_id",encodeURIComponent(client_id)).replace("$client_secret",encodeURIComponent(client_secret));
var arrBody = new byte[strBody.length];
for (var i = 0;i < strBody.length;i++){
arrBody[i] = strBody.charCodeAt(i);
}
var oHeaders = new HTTPRequestHeaders();
oHeaders.RequestPath ="http://cd.local:8082/token.svc";
oHeaders["Content-Type"] = "application/x-www-form-urlencoded";
oHeaders["Host"] = "cd.local:8082"
oHeaders.HTTPMethod = "POST";
oHeaders["Content-Length"] = arrBody.length;
var oAuthSession = FiddlerApplication.oProxy.SendRequestAndWait(oHeaders, arrBody, null, null);
if (200 == oAuthSession.responseCode) {
var oJSON = Fiddler.WebFormats.JSON.JsonDecode(oAuthSession.GetResponseBodyAsString());
oSession.RequestHeaders.Add("Authorization", oJSON.JSONObject["token_type"] + ' ' + oJSON.JSONObject["access_token"]);
}
else {
MessageBox.Show("Bad Auth: " + oAuthSession.responseCode);
}
}
If you now go back to your grapiql page, you should find that your requests are authorised. If it doesn't work, make sure that you've removed your rule out of Requestly or whatever you've been using; given two "Authorized" headers, the service will very likely not behave nicely.
There are plenty of obvious improvements that can still be made. For example, it's probably fairly easy to switch this on and off with a setting in Fiddler, or to check for an existing Authorization header.
Anyway - this is going to make my life much nicer as I play with the API.
Getting started with Insomnia as a Tridion content delivery client
Today I ran across Insomnia, which is a generic development/test client for RESTful HTTP services much along the same lines as Postman. The latter is pretty well established, but it's a paid product, and Insomnia seems at first sight to be more or less a clone, but open source and free. (That said, Postman is free to most people, and Insomnia has paid-for plugins. Everyone's got to eat, right?)
It will hardly be a surprise to the reader that my interest in this is in the context of Tridion's content delivery APIs. To be honest I haven't really spent much time getting to know Postman, preferring to make use of simple Powershell scripts for purposes such as validating that the services are running and that authentication is working. While there's much to be said for a scripted approach, I've always had niggling doubts that perhaps I'd find my way around the data a bit more easily with a GUI client. Coming across Insomnia today is my opportunity to find out whether this is so.
I started by downloading and installing the Windows version (like Postman, it's also available for Linux and Mac). So far, I've got as far as making a simple query against my content service. To do this, you have to figure your way through the somewhat arcane details of getting an OAuth token. The services on my Tridion research server are not secured in any meaningful way, but OAuth is still "switched on. That is to say, I have the out-of-the-box user accounts configured in my discovery service's cd_ambient_conf.xml along with the out-of-the-box passwords. So obviously, don't do this at home children, but hey - it's my research rig, not a production server. This being the case, I'm not giving much away by sharing the following:
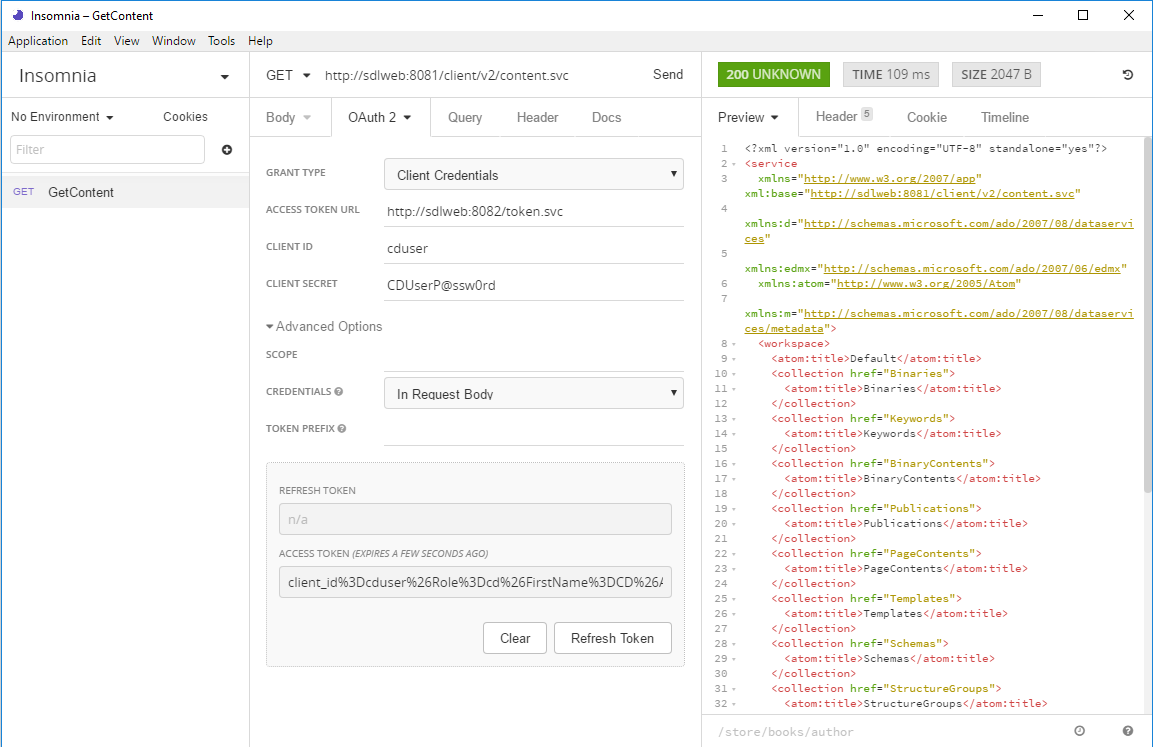
What you can see here is that my Tridion image is running at "sdlweb", so I'm issuing a GET against http://sdlweb:8081/client/v2/content.svc. Insomnia has support for variables, so I imagine you could use one for the hostname if you want to keep your tests generic.
You can also see that I've got the authentication tab open and have selected OAuth2. The first thing you need to do is select Client Credentials for the grant type. With this choice, you only need to fill in the client id and secret. (Obviously these need to match your actual security settings, and of course, you haven't left these at their defaults... right!?)
The only thing that made me scratch my head for a short moment was that when I tried with just those details, it didn't work, and I got a 400 status back. That's HTTP for "Bad request", so I went into the Advanced settings to see if there was anything I could change to make the server happier about my manners. It turns out that switching Credentials to "In Request Body" is all you need and as you can see, there's a nice green 200 status displaying, and some data from the service.
Well that's enough to get me started. Please do let me know about your experiences with Insomnia. Especially if you're a Postman maven, let me know how the two stack up against each other.
System refresh: new architecture for www.dominic.cronin.nl
It's taken a while, and the odd skinned knuckle and a bit of cursing, but I can finally announce that this site is running on...erm.. the other server. Tada! Ta-ta-ta-diddly.... daaahhhh!!!!
Um yeah - I get it. it's not so exciting is it really? The blog's still here, and it's got more or less the same content. It doesn't look any different. Maybe it's a tiny smidgin faster, but even that's more likely to do with the fact that we switched over to an ISP that actually makes use of the glass that runs in to our meter cupboard.
But I'm excited. Just a bit, anyway. Partly because it's taken me months. It needn't have, but it's the usual question of squeezing it into the cracks between all the other things that need to get done in life. That and the fact that I'm an utter cheapskate and I don't want to pay for anything. There's also plenty not to be excited about. As I said, the functionality is exactly as it was. The benefits I get from it are mostly about the ability to do things better going forward.
So what have I done? Well it all started an incredibly long time ago when I started tinkering with docker. I figured that the whole containerisation technology thing had such a lot of potential that I ought at least to run docker on my own server. After all, over the years, I'd always struggled with Plone needing to have a different version of Python than the one available in the current Gentoo ebuilds. I'd attempted a couple of things, including I think an early version of what became LXC, but then along came virtualenv, which made the whole thing moot.
Yeah, well - until I wanted to play with docker for itself. At this point, I just thought I'd install it on my server, and get going, but I immediately discovered, that the old box I was running was 32-bit, and docker is just far too hip to run on anything so old-fashioned. So I needed a new server, and once I'd realised that, that's when the whole thing started. If I was going to have a new server, why didn't I just containerise everything? It's at this point that someone inevitably chips in with a suggestion that if I weren't such a dinosaur, I'd run it on the cloud, wouldn't I? Well yes - sure! But I told you - I'm a cheapskate, and apart from that, I don't want anyone's soul-less reliability messing with my carefully constructed one-nine availability commitment.
Actually I like cloud tech, but frankly, when you look at the micro-budget that supports this site, I'd have spent all my time searching out a super-cheap host, and even then I'd have begrudged it. So my compromise with myself was that I'd build it all very cloudy, and then the world's various public clouds would be my disaster recovery plan. And so it is. If this server dies, I can get it all up in the cloud with a fairly meagre effort. Still not going to two-nines though.
So I went down to my local high street where there's a shop run by these Indian guys. They always have a good choice of "hardly used" ex-business computers. I think I shelled out a couple of hundred Euros, and then I had something with an i5 and enough memory, and a couple of stupidly big disks to make a raid. Anyway - more than enough for a web server - which is just as well, because pretty soon it ends up just being "the server", and it'll get used for all sorts of other things. All the more reason to containerise everything.
I got the thing home, and instead of doing what I've done many times before, and installing Gentoo linux, I poked around a bit on the Internet and found CoreOS. Gentoo is a masochist's delight. I mean - it runs like a sports car, but you have to own a set of spanners. CoreOS, on the other hand, is more or less maintenance free. It's built on Gentoo's build system, so it inherits the sports car mentality of only installing things you are going to use, but then the guys at CoreOS do that, and their idea of "things you are going to use" is basically everything that it takes to get containers up and keep them running, plus exactly nothing else. For the rest, it's designed for cloud use, so you can install it from bare metal to fully working just by writing a configuration file, and it knows how to update itself while running. (It has a separate partition for the new version, and it just switches over.)
So with CoreOS up and running, the next thing was to convert all the moving parts over to Docker containers. As it stands now, I didn't want to change too much of the basics, so I'm running Plone on a Gentoo container. That's way too much masochism though. I'd already been thinking I'd do a fresh one with a more generic out-of-the-box OS, and I've just realised I can pull a pre-built Plone image based on Debian (or Alpine). This gets better and better. And I can run it all up side-by-side in separate containers until I'm ready to flip the switch. Just great! Hmm... maybe my grand master plan was just to get to Plone 5!
The Gentoo container I'm using is based on one created by the Gentoo community, which you can pull from the Docker hub. Once I found this, I thought I was home and dry, but it's not really well-suited to just pulling automatically from a docker file. What they've done is to separate out the portage tree into a separate container. This is smart, because you are unlikely to want the whole of portage in your container for any given purpose that makes you want to run Gentoo. What you do instead is mount the portage data using docker's --volumes-from argument. With it mounted, you can run emerge and install whatever packages you need, and then at runtime you get to run a much slimmer system. Which is great, but it means you have to create and store your own image manually rather than using a dockerfile. (At least, that's how it ended up for a noob like me, once I realised that dockerfile doesn't have an equivalent of --volumes-from.)
My goal was to set up CoreOs to automatically pull the docker images it needed, and run some setup commands. This meant that I'd need to have my personalised Gentoo image available somewhere. Some of the data in there was sensitive, so I went looking for a private Docker registry that I could upload it to. There are plenty of private registries, but most of them aren't free. (If you don't mind the whole world pulling your containers, then free registries abound.) I eventually found https://canister.io/, which suited my needs. That said, my needs aren't much. If I ever need an alternative to canister, I'll probably look at Google Cloud Platform, which isn't free but has a private container registry where you only pay for storage and data egress, at pretty reasonable rates. Or I could just host it myself, but that's maybe too many eggs in the same basket.
Meanwhile, my very next step ought most probably be to get backups sorted out. The "Dockerish" way to do this is to run up yet another dedicated container to deal with just this concern. Then if I want to host it separately, and my backup approach changes, nothing else needs to. Once I have the backups sorted out, it will definitely be worth the while to tidy things up so that I really can just push to the cloud if needs be. The way it's set up now, I could be up and running again very quickly but we're probably talking hours rather than seconds.
I'm really enjoying the flexibility that containerisation gives me, although it's definitely important to get into the right mindset. Being able to build containers that will run on a really generic platform is quite liberating.
Getting started with SDL Web 8 and the discovery service
Well it's taken me a while to get this far, but I'm finally getting a bit further through the process of installing Web 8. My first attempt had foundered when I failed to accept the installer's defaults - it really, really wants to run the various services on different ports instead of by configuring host headers!
Anyway - this time I accepted the defaults and the content manager install seemed to go OK. (I suppose I'll set up the host header configuration manually at some point once I'm a bit more familiar with how everything hangs together.) So now I'm busy installing and configuring content delivery, and specifically the Discovery service. I got as far as this point in the documentation, where it tells you to run
java -jar discovery-registration.jar updateThis didn't work. Instead I got an error message hinting that perhaps the service ought to be running first. So after a minute or two checking whether I'd missed a step in the documentation, I went to tridion.stackexchange.com and read a couple of answers. Peter Kjaer had advised someone to run start.ps1, so I went back to have a better look. Sure enough, in the Discovery service directory, there's a readme file, with instructions for starting the service from the shell, and also for running it as a service. (This also explains why I couldn't find the Windows service mentioned in the following step in the installation documentation.)
Anyway - so I tried to run the script, and discovered that it expects to find JAVA_HOME in my environment. So I added the environment variable, and but then when I started the script it spewed out a huge long java exception saying it couldn't find the database I'd configured. But... nil desperandum, community to the rescue, and it turned out to be a simple fix.
So with that out of the way, I ran the other script - to install it as a service, and I now have a working discovery service... next step: registration
Using helpers in Tridion Razor templating
Today, for the first time, I used a helper in a Razor Tridion template. I'd made a fairly standard 'generic link' embedded schema, so that I could combine the possibility of a component link and an external link in a link list, and allow for custom link text. (Nothing to see here, move along now please.) However, when I came to template the output, I wanted to have a function that would process an individual link. A feature of Razor templating is that you can define a @helper, which is a bit like a function, except that instead of a return value, the body is an exemplar of the required output. There is also support for functions, so to lift Alex Klock's own example:
@functions {
public string HelloWorld(string name) {
return "Hello " + name;
}
}
and
@helper HelloWorld(string name) {
<div>Hello <em>@name</em>!</div>
}
will serve fairly similar purposes.
What I wanted to do today, however was slightly different; I didn't want to pass in a string, but a reference to my embedded field. All the examples on the web so far are about strings, and getting the types right proved interesting. I started out with some code like this:
@foreach(var link in @Fields.links){
@RenderLink(link);
}
So I needed a helper called RenderLink (OK - this might be a very trivial use-case, but a real problem all the same.). But what was the type of the argument? In theory, "links" is an EmbeddedSchemaField (or to give it it's full Sunday name: Tridion.ContentManager.ContentManagement.Fields.EmbeddedSchemaField) but what you get in practice is an object of type "Tridion.Extensions.Mediators.Razor.Models.DynamicItemFields". I'd already guessed this by poking around in the Razor Mediator sources, but after a few of my first experiments went astray, I ended up confirming that with @link.GetType().FullName
Well I tried writing a helper like this:
@using Tridion.Extensions.Mediators.Razor.Models
@helper RenderLink(DynamicItemFields link){
... implementation
}
but that didn't work, because when you try to call the methods on 'link' they don't exist.
And then, just for fun, of course, I tried
@using Tridion.ContentManager.ContentManagement.Fields
@helper RenderLink(EmbeddedSchemaField link){
... implementation
}
but that was just going off in an even worse direction. Yeah, sure, that type would have had the methods, but what I actually had hold of was a DynamicItemFields. Eventually, I remembered some hints in the mediator's documentation and tried using the 'dynamic' keyword. This, it turns out, is what you need. The 'dynamic' type lets you invoke methods at run-time without the compiler needing to know about them. (At last, I was starting to understand some of the details of the mediator's implementation!)
@helper RenderLink(dynamic link){
... implementation
}
This may be obvious with hindsight (as the old engineers' joke has it ... for some value of 'obvious') . For now, I'm writing another blog post tagged #babysteps and #notetoself, and enjoying my tendency to take the road less travelled.
| TWO roads diverged in a yellow wood, | |
| And sorry I could not travel both | |
| And be one traveler, long I stood | |
|
And looked down one as far as I could |
|
| To where it bent in the undergrowth; | |
| Then took the other, as just as fair, | |
| And having perhaps the better claim, | |
|
Because it was grassy and wanted wear; |
|
| Though as for that the passing there | |
| Had worn them really about the same, | |
| And both that morning equally lay | |
|
In leaves no step had trodden black. |
|
| Oh, I kept the first for another day! | |
| Yet knowing how way leads on to way, | |
| I doubted if I should ever come back. | |
|
I shall be telling this with a sigh |
|
| Somewhere ages and ages hence: | |
| Two roads diverged in a wood, and I— | |
| I took the one less traveled by, | |
| And that has made all the difference. |
-- Robert Frost