Dominic Cronin's weblog
Tridion Core service PowerShell settings for SSO-enabled CMS
In a Single-Sign-On (SSO) configuration, it's necessary to use Basic Authentication for web requests to the Tridion Content Manager from the browser. This is probably the oldest way of authenticating a web request, and involves sending the password in plain over the wire. This allows the SSO system to make use of the password, which would be impossible if you used, for example, Windows Authentication. The down side of this is that you'd be sending the password in plain over the wire... can't have that, so we encrypt the connection with HTTPS.
What I'm describing here is the relatively simple use case of using the powershell module to log in to an SSO-enabled site using a domain account. Do please note that this won't work if you're expecting to authenticate using SSO. Then you'll need to mess around with federated security tokens and such things. My use case is a little simpler as I have a domain account I can log in with. As the site is set up to support most of the users coming in via SSO, these are the settings I needed, and hence this "note to self" post. If anyone has gone the extra mile to get SSO working, I'd be interested to hear about it.
So this is how it ends up looking:
Import-Module Tridion-CoreService
Set-TridionCoreServiceSettings -HostName 'contentmanager.company.com'
Set-TridionCoreServiceSettings -Version 'Web-8.5'
Set-TridionCoreServiceSettings -CredentialType 'Basic'
Set-TridionCoreServiceSettings -ConnectionType 'Basic-SSL'
$ServiceAccountPassword = ConvertTo-SecureString 'secret' -AsPlainText -Force
$ServiceAccountCredential = New-Object System.Management.Automation.PSCredential ('DOMAIN\login', $ServiceAccountPassword)
Set-TridionCoreServiceSettings -Credential $ServiceAccountCredential
$core = Get-TridionCoreServiceClient
$core.GetApiVersion() # The simplest test
This is just an example, so I've stored my password in the script. The password is 'secret'. It's a secret. Don't tell anyone. Still - even though I'm a bit lacking in security rigour, the PowerShell isn't. It only wants to work with secure strings and so should you. In fact, it's not much more fuss to work with Convert-ToSecureString and friends to keep everything ship shape and Bristol fashion.
Using the Tridion PowerShell module in a restricted environment
At some point, pretty much every Tridion specialist is going to want to make use of Peter Kjaer's Tridion Core Service Powershell modules. The modules come with batteries included, and if you look at the latest version, you'll see that the modules are available from the PowerShell gallery, and therefore a simple install via Install-Module should "just work".
Most of us spend a lot of our time on computers that are behind a corporate firewall, and on which the operating system is managed for us by people whose main focus is on not allowing us to break anything. I recently found myself trying to install the modules on a system with an older version of PowerShell where Install-Module wasn't available. The solution for this is usually to install the PowerShellGet module which makes Install-Module available to you. In this particular environment, I knew that various other difficulties existed, notably with the way the PowerShell module path is managed. Installing a module would first require a solution to the problem of installing modules. In the past, I'd made a custom version of the Tridion module as a workaround, but now I was trying to get back to a clean copy of the latest, greatest version. Hacking things by hand would defeat my purpose.
It turned out that I was able to clone the GIT repository, so I had the folder structure on disk. (Failing that I could have tried downloading a Zip file from GitHub.)
Normally, you install your modules in a location on the Module Path of your PowerShell, and the commonest of these locations is the WindowsPowerShell folder in your Documents folder. (There are other locations, and you can check these with "gc Env:\PSModulePath".) As I've mentioned, in this case, using the normal Module Path mechanism was problematic, so I looked a little further. It turned out the solution was much simpler than I had feared. You can simply load a module by specifying its location when you call ImportModule. I made sure that the tridion-powershell-modules folder I'd got from GIT was in a known location relative to the script file from which I wanted to invoke it, and then called Import-Module using the location of Tridion-CoreService.psd1
$scriptLocation = Split-Path ((Get-Variable MyInvocation -Scope 0).Value).MyCommand.Path
import-module $scriptLocation\..\tridion-powershell-modules\CoreService\Tridion-CoreService.psd1
Getting the script location from the built-in MyInvocation variable is ugly, but pretty much standard PowerShell. Anyway - this works, and I now have a strategy for setting up my scripts to use the latest version of the core service module. Obviously, if you want the Alchemy or Content Delivery module, a similar technique ought to work.
Tridion Sites 9.... and beyond!!!
A month or so ago, Amsterdam was again host to the Tridion Developer Summit. This is a great event for anyone involved with Tridion, and each year it goes from strength to strength. This year, a lot of the focus, understandably, was on the forthcoming release of Tridion Sites 9, which will be part of Tridion DX. We heard speakers from SDL and from the wider community talking on a variety of topics. In one sense, I suppose, the usual mixture, but there's always a certain excitement when a new major release is coming out. (Yes, I know we don't call them major's any more, but still, we're looking at brand new APIs that none of us have used yet: that's a major in my book!)
The talks covered everything from the new user interface, to the combined play with structured content that the DX platform will offer, to new services based on GraphQL (which is probably becoming the "must study" topic). Other speakers covered integrations and extension points and javascript and, well, you name it. If you spoke, and I haven't mentioned your bit, please don't take offence!
It was a great conference, which I thoroughly enjoyed; not least because of the chance to catch up with everyone. But a month later, I just want to share the thing that really blew me away and stuck with me. The new product release isn't finished just yet, but the scope is more or less fixed. If a feature isn't already in, then it probably won't be in Tridion sites 9. That said, the guys in R&D are not standing still, and they are already looking forward to the next thing. Which brings me to the buzz moment of this year's summit. I'm not sure if Likhan Siddiquee was even meant to be presenting in the main theatre at that moment, but well... Likhan's an enthusiast. If this guy's got some amazing new tech to show, try and stop him! (Good luck with that!) So he comes in and just kind of tags along after a couple of the other SDL presenters. He's showman enough that it could have all been staged, but he managed to make it seem as though... well... he just had this cool stuff on his laptop and.... did we maybe have five or ten minutes?
So he walks on stage carrying his kid - a babe in arms! Start em young, I suppose. Anyway child-care and work-life balance obviously hold no fears for Likhan. He hands off the baby to his able assistant, and proceeds to unveil the geeky goodies. What did he have? Nothing less than the Tridion kernel running on .NET core! Sure - this was a pre-preview. Hot off the press. No user interface, and only a bare-bones system, but sure enough he got it going from the command prompt with the "dotnet" command and proceded to start hitting service endpoints with a web browser. Wow!
It was a moment in time. You had to be there. I'm sure we'll be waiting a while to see a production version. For sure it won't make it into the 9 release, but who cares? Hey for a lot of people, they won't even notice. Nothing wrong with running Windows Server, is there? Still this will open up lots of possibilities for different kinds of hosting options, and for those of us who like to run a "fifth environment" it's going to be awesome. Everything on linux containers. What's not to like?
Thanks to all those who took part in the Summit. You were all great, but especially thanks Likhan for that inspiring moment!
Preparing HTML data for use in a Tridion Rich Text Format area
I recently had to create some Tridion components from code via the core service. The incoming data was in the form of HTML, and not XML in the XHTML namespace, which is what is required for a Tridion RTF area. I'd also had to do some preparatory clean-up of the data, and by the time I wanted to fix up the namespaces, I already had the input data in an XLinq XElement.
These days, if I'm processing XML in .NET, I'm quite likely to use XLinq. It's taken me a while to get comfortable with some of its idioms. The technique I ended up using is similar to the classic approach we typically adopt in XSLT, starting with an identity transform and making a couple of minor tweaks to the data as it goes through.
So, mostly by way of a "note to self", here's how it looks in XLinq. All you need to do is pass in your XElement containing your XHTML, and it will rip through all the elements and put them in the XHTML namespace, leaving all the attributes and other nodes untouched.
public XNode PutHtmlElementsInXhtmlNamespace(XNode input){
XNamespace xhtmlNs = "http://www.w3.org/1999/xhtml";
var element = input as XElement;
if (element != null)
{
XName name = xhtmlNs + element.Name.LocalName;
return new XElement(name,element.Attributes(),
element.Nodes().Select(n => PutHtmlElementsInXhtmlNamespace(n)));
}
return input;
}
In this way you can easily create data that's suitable for use in an RTF. Piecing the rest of a Content element together with XElement is pretty easy too, or of course, you can use the venerable Fields class for the rest.
Getting started with Insomnia as a Tridion content delivery client
Today I ran across Insomnia, which is a generic development/test client for RESTful HTTP services much along the same lines as Postman. The latter is pretty well established, but it's a paid product, and Insomnia seems at first sight to be more or less a clone, but open source and free. (That said, Postman is free to most people, and Insomnia has paid-for plugins. Everyone's got to eat, right?)
It will hardly be a surprise to the reader that my interest in this is in the context of Tridion's content delivery APIs. To be honest I haven't really spent much time getting to know Postman, preferring to make use of simple Powershell scripts for purposes such as validating that the services are running and that authentication is working. While there's much to be said for a scripted approach, I've always had niggling doubts that perhaps I'd find my way around the data a bit more easily with a GUI client. Coming across Insomnia today is my opportunity to find out whether this is so.
I started by downloading and installing the Windows version (like Postman, it's also available for Linux and Mac). So far, I've got as far as making a simple query against my content service. To do this, you have to figure your way through the somewhat arcane details of getting an OAuth token. The services on my Tridion research server are not secured in any meaningful way, but OAuth is still "switched on. That is to say, I have the out-of-the-box user accounts configured in my discovery service's cd_ambient_conf.xml along with the out-of-the-box passwords. So obviously, don't do this at home children, but hey - it's my research rig, not a production server. This being the case, I'm not giving much away by sharing the following:
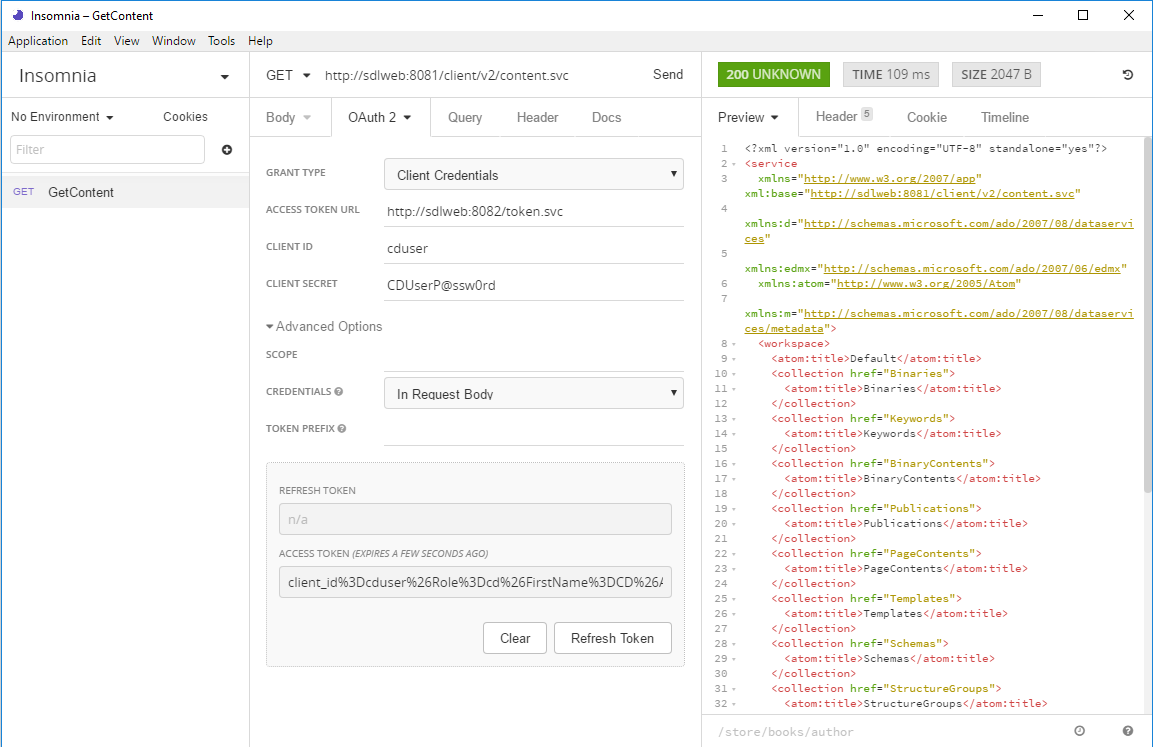
What you can see here is that my Tridion image is running at "sdlweb", so I'm issuing a GET against http://sdlweb:8081/client/v2/content.svc. Insomnia has support for variables, so I imagine you could use one for the hostname if you want to keep your tests generic.
You can also see that I've got the authentication tab open and have selected OAuth2. The first thing you need to do is select Client Credentials for the grant type. With this choice, you only need to fill in the client id and secret. (Obviously these need to match your actual security settings, and of course, you haven't left these at their defaults... right!?)
The only thing that made me scratch my head for a short moment was that when I tried with just those details, it didn't work, and I got a 400 status back. That's HTTP for "Bad request", so I went into the Advanced settings to see if there was anything I could change to make the server happier about my manners. It turns out that switching Credentials to "In Request Body" is all you need and as you can see, there's a nice green 200 status displaying, and some data from the service.
Well that's enough to get me started. Please do let me know about your experiences with Insomnia. Especially if you're a Postman maven, let me know how the two stack up against each other.
Stripping namespace declarations from XML
I've recently been working on an application that will allow members of our content management teams to search within a chosen folder in Tridion for specific content. You might think that's well enough covered by the built-in search functionality, but we're heading towards a search and replace feature, so we pretty much have to process the content ourselves. In the end users' view of the world, a Rich Text field in a component has... well... a rich text view, and, for the power-users, a Source tab where you can see the underlying HTML. That's all fine, but once you get to the technical implementation, it's a bit more complicated, and we'll end up replicating some of Tridion's own smoke and mirrors to present a view to the users that's consistent with what they are used to. This means not only that we need to be able to translate from text to HTML, but also from "XML in the XHTML namespace" to HTML. One of the bulding blocks we need to do this is the ability to take XML with namespace declarations, and get rid of them so that the result isn't in a namespace.
A purist (such as myself) might say that the only correct way to parse XML is with an XML parser, and just in case you've never ended up there, I heartily recommend that you read this answer on Stack Exchange before proceding further. Still - in this case, what I want to do is amenable to RegExes, and yes, I know: now I have two problems. Anyway - FWIW - I started this at the office, thinking I'd just quickly Google for a namespace-stripping regex and I'd be on my way. Suffice it to say that the Internet is rubbish at this. I ended up with a page of links to rubbish regexes that just weren't going to float my boat. So I mailed the problem to myself at home, and today, in the quiet of a Sunday morning, it didn't seem quite so daunting. Actually, I'm still considering whether an XML-parser approach, or an XSLT might not be better, and I may end up there if my needs turn out to be more complex, but for now, here's the namespace stripper.
static Regex namespaceRegex = new Regex(@"
xmlns # literal (:[^\s=]+)? # : followed by one or more non-whitespace, non-equals chars \s* # optional whitespace = # literal \s* # optional whitespace (?<quote>['""]) # Either a single or double quote - giving it the name 'quote' for back-reference .+? # Non-greedily match anything \k<quote> # The end-quote to match the one we found earlier ", RegexOptions.Singleline | RegexOptions.IgnoreCase | RegexOptions.IgnorePatternWhitespace);
public static string RemoveNamespacesFromDocument(string xml) { return namespaceRegex.Replace(xml, string.Empty); }
Of course, this is written in C#, and I'm taking advantage of the IgnorePatternWhitespace feature in .NET regexes, which allows for the copious comments that might well be necessary if I ever have to actually read this code instead of just writing it.
But just in case you are hardcore, and all that named matches and commenting fuss is for wusses, here's the TL;DR...
@"(?is)xmlns(:[^\s=]+)?\s*=\s*(['""]).+?\2"
What's not to like? :-)
deployer-conf.xml barfs on the BOM
Today I was working on some scripts to provision, among other things, the SDL Web deployer service. It should have been straightforward enough, I thought. Just copy the relevant directory and fix up a couple of configuration files. Well I got that far, at least, but my deployer service wouldn't start. When I looked in the logs and found this:
2017-09-16 19:20:21,907 ERROR NonLegacyConfigConditional - The operation could not be performed.
com.sdl.delivery.configuration.ConfigurationException: Could not load legacy configuration
at com.sdl.delivery.deployer.configuration.DeployerConfigurationLoader.configure(DeployerConfigurationLoader.java:136)
at com.sdl.delivery.deployer.configuration.folder.NonLegacyConfigConditional.matches(NonLegacyConfigConditional.java:25)
I thought it was going to be a right head-scratcher. Fortunately, a little further down there was something a little more clue-bestowing:
Caused by: org.xml.sax.SAXParseException: Content is not allowed in prolog.
at org.apache.xerces.parsers.DOMParser.parse(Unknown Source)
at org.apache.xerces.jaxp.DocumentBuilderImpl.parse(Unknown Source)
at com.tridion.configuration.XMLConfigurationReader.readConfiguration(XMLConfigurationReader.java:124)
So it was about the XML. It seems that Xerxes thought I had content in my prolog. Great! At least, despite its protestations about a legacy configuration, there was a good clear message pointing to my "deployer-conf.xml". So I opened it up, thinking maybe my script had mangled something, but it all looked great. Then some subliminal, ancestral memory made me think of the Byte Order Mark. (OK, OK, it was Google, but honestly... the ancestors were there talking to me.)
I opened up the deployer-conf.xml again, this time in a byte editor, and there it was, as large as life:
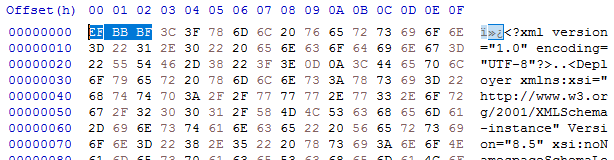
Three extra bytes that Xerxes thought had no business being there: the Byte Order Mark, or BOM. (I had to check that. I'm more used to a two-byte BOM, but for UTF-8 it's three. And yes - do follow this link for a more in-depth read, especially if you don't know what a BOM is for. All will be revealed.)
What you'll also find if you follow that link is that Xerxes is perfectly entitled to think that, as it's a "non-normative" part of the standard. Great eh?
Anyway - so how did the BOM get there, and what was the solution?
My provisioning scripts are written in Windows PowerShell, and I'd chosen to use PowerShell's "native" XML processing, which amounts to System.Xml.XmlDocument. In previous versions of these scripts, I'd used XLinq, but it's not really a good fit with PowerShell as you can't really use XPath without extension methods. So I gave up XLinq's ease of parsing fragments for a return to XmlDocument. To be honest, I wouldn't be surprised if the BOM problem also happens with XLinq: after all, it's Xerxes that's being fussy - you could argue Microsoft is playing "by the book".
So what I was doing was this.
$config = [xml](gc $deployerConfig)
Obviously, $deployerConfig refers to the configuration file, and I'm using Powershell's Get-Content cmdlet to read the file from disk. The [xml] cast automatically loads it into an XmlDocument, represented by the $config variable. I then do various manipulations in the XmlDocument, and eventually I want to write it back to disk. The obvious thing to do is just use the Save() method to write it back to the same location, like this:
$config.Save($deployerConfig)
Unfortunately, this gives us the unwanted BOM, so instead we have to explicitly control the encoding, like this:
$encoding = new-object System.Text.UTF8Encoding $false
$writer = new-object System.IO.StreamWriter($deployerConfig,$false,$encoding) $config.Save($writer) $writer.Close()
As you can see, we're still using Save(), but this time with the overload that writes to a stream, and also allows us to pass in an encoding. This seems to work fine, and Xerces doesn't cough it's lunch up when you try to start the deployer.
I think it will be increasingly common for people to script their setups. SDL's own "quickinstall" doesn't use an XML parser at all, but simply does string replacements based on its own, presumably hand-made, copies of the configuration files. Still - one of the obvious benefits of having XML configuration files is that you can use XML processing tools to manipulate them, so I hope future versions of the content delivery microservices will be more robust in this respect. Until then, here's the workaround. As usual - any feedback or alternative approaches are welcome.
Connecting to Microsoft SQL Server Developer from Tridion Content Delivery
I've recently been setting up a development image for SDL Web 8.5, and as it's only for use on my development rig, it's fair game to use Microsoft SQL Server Developer edition. It's not supported by SDL, but it's close enough to make it a reasonable risk for my purposes. I got the databases set up and the content manager installed OK, so I moved on to the content delivery stack.
First I hacked together a database test script to make sure I had all the logins correct etc. I've done it this way for years, and you may have seen my blog about it quite a long time ago. Everything seemed fine.
I'd started with the Discovery service, and I'd configured the cd_storage_conf.xml with the relevant database settings I'd just tested. How hard could it be? Except that it didn't work. I got messages in the logs telling me to check my firewall. Doh! Off I went and opened up the firewall ports for my microservices (which I'd forgotten to do) and also 1433 for MSSQL. Still no joy.
Somewhere along the way I'd also disabled loopback checking and double-checked a bunch of other things that can cause trouble. No joy.
I went back to my database test script a few times. It uses a System.Data.SqlClient.SqlConnection to execute a simple command. The connection string specifies '(local)' as the server. I'd had trouble with using '(local)' in the cd_storage_conf.xml in a previous version of Tridion, so I had specified 'localhost' instead, and then when that didn't work, a different name that mapped to the same interface. Still nothing.
The troubling thing was that the test script worked fine. Why was that, when Tridion's java stack had trouble doing the same thing? I should have cottoned on to this way earlier, but eventually I started checking to see if there was actually anything listening on 1433. No there wasn't. Well that helped. And then I started poking around in the network configuration of SQL Server. Sure enough: TCP/IP wasn't enabled. I'm still not sure if this is a Developer edition thing. I seem to recall having come across it before. I'm not the only one. Now that I know the answer, finding a suitable Stack Overflow answer is easy! Maybe I'd had trouble with SQLEXPRESS.
Anyway, at least that explained why my test script worked OK. The SqlConnection client sees '(local)' and is then able to attempt a named pipes or shared memory connection as well as TCP/IP. The java client, on the other hand, doesn't have this repertoire of options and if TCP/IP fails, it's over.
Anyway - now it's fixed. Just time for a quick Note To Self, and on with the rest of my system.
Character encodings and the SDL Web 8 deployer - a journey through double-encoded UTF-8
I spent some time yesterday and today working with a colleague to resolve an encoding issue in our new SDL Web 8.5 publishing systems. It's a migration from an older Tridion implementation that manages several portals, including a very old one in which the default encoding is ISO-8859-1.
For various historical reasons, even for the portals which use UTF-8, the code page has always been set explicitly in the template, using something like setCodePage(1252) or setCodePage(65001) in the vbScript of the page template. (The pedantic among you may have noted that code page 1252 is not the same as ISO-8859-1, and even though some of the characters we were having trouble with were, indeed, quotation marks in the control codes range, I'm going to let that particular distinction slide for the purpose of this blog post. An exercise for the student, as they used to say... )
So most of the sites are in UTF-8, and had setCodePage(65001) in the templates. These worked fine with the out-of-the-box installation of the deployer service. Even the gnarliest of funky characters were transmitted faithfully from end to end. The trouble was with the old site that had code page 1252. On this site, any vaguely interesting characters were incorrectly displayed. OK - this might not have been too much of a surprise.
In SDL Web 8, publication targets have been replaced as part of the move to the new "Topology Manager"-based architecture. So where we'd previously had the option to specify a default encoding on a publication target, now the matching configuration had moved to the deployer. (Or at least to the CD environment - strictly it's a Deployer Capability which is exposed by the Discovery service.) The general assumption seems to be that all sites sharing a deployer will also share an encoding. It's not actually so daft an idea. Most sites these days just use UTF-8 and have done with it. Even if you really, really, really want to have sites with different encodings, well you could always run up another environment, couldn't you? Microservices FTW!
By the time we'd come to this understanding, my colleague had already spent quite some time experimenting with different settings. We'd ended up being able to show that we could get one or the other working, but not both at the same time. We didn't want to set up extra CD environments throughout the DTAP, so the obvious approach was to fix up the old site to use UTF-8. What's not to like? In the beginning I hadn't realised that the old site also used setCodePage(1252) - it was buried pretty deep. So my first approach was simply to get into the templating and fix up the JSP page directive so that we were sending the right contentType header, and specifying pageEncoding="UTF-8". However... no joy.. we still had bad characters, so I then dug deep enough to find the relevant routine. I duly changed it to setCodePage(65001) and smugly headed off to get a cup of coffee while it all published.
By the time we had some published output to look at, we realised, that the "interesting" characters were now double-encoded UTF-8. (You can usually tell this just by looking. You tend to see pairs of characters, the first of which is often an accented A, like å or Ã.) So what was happening?
TL;DR
- It turns out that even in Web 8, the renderer is capable of creating transport packages in a variety of encodings. If you specify 1252 programatically in the template, the page in the zip file will be encoded with that encoding. Likewise for 65001/UTF-8. Not only will the renderer use the specified encoding, but it will tell the truth about this when it writes the <codepage> element in the pages.xml file.
- With neither a publication target nor a programatically specified code page, UTF-8 will be used in the transport package.
- No further encoding will take place until the package reaches the deployer and is unzipped.
- When reading the newly received page, the deployer will use the current default encoding of its JVM. If you don't specify this, the default will be the default encoding of your operating system. On Windows, usually code page 1252, and on Linux usually UTF-8. (Obviously, this means it's ignoring the information about encoding that's embedded in the deployment package. You could argue that this might be a bug.)
- The installation scripts for the deployer configure the service to pass various arguments to the JVM on startup, including "-Dfile.encoding=UTF-8". This matches the assumption that you have no publication target and the incoming encoding is therefore UTF-8.
- In our case, we left the Deployer Capability setting at UTF-8.
The reason we had seen double-encoded UTF-8 was that after the various experimentation, we no longer had the -Dfile.encoding=UTF-8 parameter controlling the JVM startup. Without this, when we were successfully sending UTF-8 in the deployment package, it was being read in as cp1252, and then dutifully re-encoded to the encoding specified in the Deployer Capability registration: UTF-8.
Without this setting, at one point we had also successfully used cp1252, with the output rendered correctly as UTF-8.
Once we'd figured it all out, we got the whole thing working with all sites running UTF-8. This is almost certainly better than having to worry about a variety of different settings in your infrastructure.
As with any investigation of encodings, a byte-editor is your friend, and plenty of patience to look carefully at what you're seeing. In the end, you'll get there!
Decoding webdav URLs (or how to avoid going cross-eyed reading your error messages)
I was doing some Content Porting the other day. When moving code up the DTAP street the general practice is to switch off dependency management and, well, manage the dependencies yourself. This is great for a surgical software release, where you know exactly what's in the package and can be sure that you aren't unintentionally releasing something you hadn't planned to, but....
Yeah - there's always a but. In this case, you have to make sure that all the items your exported items depend on are present, either in the export or in the target system. Sometimes you miss one, and during the import you get a nice error message saying which item is missing. Unfortunately, the location of the item is given as a WebDAV URL. If the item in question has lots of spaces, quote marks, or other special characters in it, by the time you get to read the URL in all its escaped glory, it can be a complete alphabet soup.
So there I was, squinting at some horrible URL and mentally parsing out the escape sequences to figure out what I was looking at.. when it dawned on me. Decoding encoded URLs is not work for humans - we have computers for that. So I fired up my trusty Powershell, thinking "hey, I have the awesome power of the .NET framework at my disposal". As it turns out, the HttpUtility libraries that most devs are familiar with is probably not there in your ordinary desktop OS, but System.Net.WebUtility is. So if you've copied a webdav url into your paste buffer, you can open the shell, type in
[net.webutility]::Ur
From here on tab completion will fill in the rest of UrlDecode, and with one or two more keystrokes and a right-mouse-click you have something like this:
[net.webutility]::UrlDecode("/webdav/Some%20Publication/This%20%26%20that/More%20%22stuff%22%20to%20read/a%20soup%C3%A7on%20of%20something")
and then hitting enter gets you this:
/webdav/Some Publication/This & that/More "stuff" to read/a soupçon of something
which is much more readable.
Of course, if even that is too much typing for you, you can stick something like this in your profile:
function decode ($subject) {
[net.webutility]::UrlDecode($subject)
}
Of course, none of this is strictly necessary - you can always stare at the WebDAV URLs and decipher them as an exercise in mental agility, but some days you just want the easy life.