Dominic Cronin's weblog
deployer-conf.xml barfs on the BOM
Today I was working on some scripts to provision, among other things, the SDL Web deployer service. It should have been straightforward enough, I thought. Just copy the relevant directory and fix up a couple of configuration files. Well I got that far, at least, but my deployer service wouldn't start. When I looked in the logs and found this:
2017-09-16 19:20:21,907 ERROR NonLegacyConfigConditional - The operation could not be performed.
com.sdl.delivery.configuration.ConfigurationException: Could not load legacy configuration
at com.sdl.delivery.deployer.configuration.DeployerConfigurationLoader.configure(DeployerConfigurationLoader.java:136)
at com.sdl.delivery.deployer.configuration.folder.NonLegacyConfigConditional.matches(NonLegacyConfigConditional.java:25)
I thought it was going to be a right head-scratcher. Fortunately, a little further down there was something a little more clue-bestowing:
Caused by: org.xml.sax.SAXParseException: Content is not allowed in prolog.
at org.apache.xerces.parsers.DOMParser.parse(Unknown Source)
at org.apache.xerces.jaxp.DocumentBuilderImpl.parse(Unknown Source)
at com.tridion.configuration.XMLConfigurationReader.readConfiguration(XMLConfigurationReader.java:124)
So it was about the XML. It seems that Xerxes thought I had content in my prolog. Great! At least, despite its protestations about a legacy configuration, there was a good clear message pointing to my "deployer-conf.xml". So I opened it up, thinking maybe my script had mangled something, but it all looked great. Then some subliminal, ancestral memory made me think of the Byte Order Mark. (OK, OK, it was Google, but honestly... the ancestors were there talking to me.)
I opened up the deployer-conf.xml again, this time in a byte editor, and there it was, as large as life:
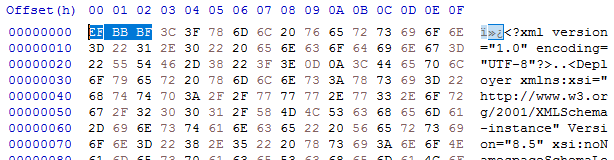
Three extra bytes that Xerxes thought had no business being there: the Byte Order Mark, or BOM. (I had to check that. I'm more used to a two-byte BOM, but for UTF-8 it's three. And yes - do follow this link for a more in-depth read, especially if you don't know what a BOM is for. All will be revealed.)
What you'll also find if you follow that link is that Xerxes is perfectly entitled to think that, as it's a "non-normative" part of the standard. Great eh?
Anyway - so how did the BOM get there, and what was the solution?
My provisioning scripts are written in Windows PowerShell, and I'd chosen to use PowerShell's "native" XML processing, which amounts to System.Xml.XmlDocument. In previous versions of these scripts, I'd used XLinq, but it's not really a good fit with PowerShell as you can't really use XPath without extension methods. So I gave up XLinq's ease of parsing fragments for a return to XmlDocument. To be honest, I wouldn't be surprised if the BOM problem also happens with XLinq: after all, it's Xerxes that's being fussy - you could argue Microsoft is playing "by the book".
So what I was doing was this.
$config = [xml](gc $deployerConfig)
Obviously, $deployerConfig refers to the configuration file, and I'm using Powershell's Get-Content cmdlet to read the file from disk. The [xml] cast automatically loads it into an XmlDocument, represented by the $config variable. I then do various manipulations in the XmlDocument, and eventually I want to write it back to disk. The obvious thing to do is just use the Save() method to write it back to the same location, like this:
$config.Save($deployerConfig)
Unfortunately, this gives us the unwanted BOM, so instead we have to explicitly control the encoding, like this:
$encoding = new-object System.Text.UTF8Encoding $false
$writer = new-object System.IO.StreamWriter($deployerConfig,$false,$encoding) $config.Save($writer) $writer.Close()
As you can see, we're still using Save(), but this time with the overload that writes to a stream, and also allows us to pass in an encoding. This seems to work fine, and Xerces doesn't cough it's lunch up when you try to start the deployer.
I think it will be increasingly common for people to script their setups. SDL's own "quickinstall" doesn't use an XML parser at all, but simply does string replacements based on its own, presumably hand-made, copies of the configuration files. Still - one of the obvious benefits of having XML configuration files is that you can use XML processing tools to manipulate them, so I hope future versions of the content delivery microservices will be more robust in this respect. Until then, here's the workaround. As usual - any feedback or alternative approaches are welcome.
Character encodings and the SDL Web 8 deployer - a journey through double-encoded UTF-8
I spent some time yesterday and today working with a colleague to resolve an encoding issue in our new SDL Web 8.5 publishing systems. It's a migration from an older Tridion implementation that manages several portals, including a very old one in which the default encoding is ISO-8859-1.
For various historical reasons, even for the portals which use UTF-8, the code page has always been set explicitly in the template, using something like setCodePage(1252) or setCodePage(65001) in the vbScript of the page template. (The pedantic among you may have noted that code page 1252 is not the same as ISO-8859-1, and even though some of the characters we were having trouble with were, indeed, quotation marks in the control codes range, I'm going to let that particular distinction slide for the purpose of this blog post. An exercise for the student, as they used to say... )
So most of the sites are in UTF-8, and had setCodePage(65001) in the templates. These worked fine with the out-of-the-box installation of the deployer service. Even the gnarliest of funky characters were transmitted faithfully from end to end. The trouble was with the old site that had code page 1252. On this site, any vaguely interesting characters were incorrectly displayed. OK - this might not have been too much of a surprise.
In SDL Web 8, publication targets have been replaced as part of the move to the new "Topology Manager"-based architecture. So where we'd previously had the option to specify a default encoding on a publication target, now the matching configuration had moved to the deployer. (Or at least to the CD environment - strictly it's a Deployer Capability which is exposed by the Discovery service.) The general assumption seems to be that all sites sharing a deployer will also share an encoding. It's not actually so daft an idea. Most sites these days just use UTF-8 and have done with it. Even if you really, really, really want to have sites with different encodings, well you could always run up another environment, couldn't you? Microservices FTW!
By the time we'd come to this understanding, my colleague had already spent quite some time experimenting with different settings. We'd ended up being able to show that we could get one or the other working, but not both at the same time. We didn't want to set up extra CD environments throughout the DTAP, so the obvious approach was to fix up the old site to use UTF-8. What's not to like? In the beginning I hadn't realised that the old site also used setCodePage(1252) - it was buried pretty deep. So my first approach was simply to get into the templating and fix up the JSP page directive so that we were sending the right contentType header, and specifying pageEncoding="UTF-8". However... no joy.. we still had bad characters, so I then dug deep enough to find the relevant routine. I duly changed it to setCodePage(65001) and smugly headed off to get a cup of coffee while it all published.
By the time we had some published output to look at, we realised, that the "interesting" characters were now double-encoded UTF-8. (You can usually tell this just by looking. You tend to see pairs of characters, the first of which is often an accented A, like å or Ã.) So what was happening?
TL;DR
- It turns out that even in Web 8, the renderer is capable of creating transport packages in a variety of encodings. If you specify 1252 programatically in the template, the page in the zip file will be encoded with that encoding. Likewise for 65001/UTF-8. Not only will the renderer use the specified encoding, but it will tell the truth about this when it writes the <codepage> element in the pages.xml file.
- With neither a publication target nor a programatically specified code page, UTF-8 will be used in the transport package.
- No further encoding will take place until the package reaches the deployer and is unzipped.
- When reading the newly received page, the deployer will use the current default encoding of its JVM. If you don't specify this, the default will be the default encoding of your operating system. On Windows, usually code page 1252, and on Linux usually UTF-8. (Obviously, this means it's ignoring the information about encoding that's embedded in the deployment package. You could argue that this might be a bug.)
- The installation scripts for the deployer configure the service to pass various arguments to the JVM on startup, including "-Dfile.encoding=UTF-8". This matches the assumption that you have no publication target and the incoming encoding is therefore UTF-8.
- In our case, we left the Deployer Capability setting at UTF-8.
The reason we had seen double-encoded UTF-8 was that after the various experimentation, we no longer had the -Dfile.encoding=UTF-8 parameter controlling the JVM startup. Without this, when we were successfully sending UTF-8 in the deployment package, it was being read in as cp1252, and then dutifully re-encoded to the encoding specified in the Deployer Capability registration: UTF-8.
Without this setting, at one point we had also successfully used cp1252, with the output rendered correctly as UTF-8.
Once we'd figured it all out, we got the whole thing working with all sites running UTF-8. This is almost certainly better than having to worry about a variety of different settings in your infrastructure.
As with any investigation of encodings, a byte-editor is your friend, and plenty of patience to look carefully at what you're seeing. In the end, you'll get there!
Why can't I get my special characters to display properly?
Today there was a question (http://tridion.stackexchange.com/q/2891/129) on the Tridion Stack Exchange that referred to putting superscript characters in a non-RTF field in Tridion. I started to answer it there, but soon realised that my answer was for a rather broader question - "How can I figure it out if funky characters don't display properly?"
- Install a good byte editor. I personally use a freeware tool: http://mh-nexus.de/en/
- Understand how UTF-8 works and be prepared to decode characters with a pencil and a sheet of paper. Make reference to http://www.ietf.org/rfc/rfc3629.txt and particularly the table on page 3. This way you can translate UTF-8 to Unicode.
- Use the code charts at www.unicode.org/charts to verify the character in Unicode.
E2 84 A2
11100010 10000100 10100010
0010000100100010